
[CS] 무중단 시스템의 HA와 배포 전략, 세션 복구
먼저 무중단 시스템을 운영하는데 어떤 전략들이 사용되는지에 대해 간단하게 알아보는 포스트이니 기술적 구현이나 실제로 적용하는 내용은 아니라는 것을 알린다.
무중단? 필요성?
일단 무중단 서비스라는 것 부터 짚고 넘어가보자.
단어 자체에서도 알 수 있듯이 무(無) + 중단(中断), 중간에 끊기지 않고 24/365 서비스를 언제든지 사용할 수 있는 상태로 유지 한다는 것을 의미한다.
클라이언트가 서비스를 이용하는데 있어 서비스가 중단되면 유실되는 데이터가 생길 수도 있고, 이로인해 큰 피해를 입을 수 있다.
이를 방지하기 위해서 무중단 서비스를 운영하는데, 그렇다면 서비스가 중단되는 상황은 어떤게 있을까?
서비스 중단의 원인.
하드웨어 문제
서비스를 운영하는데 필요한 장비들이 제 기능을 못하는 경우이다.
라우터, 스위치, 방화벽 등의 네트워크 장비의 고장이라던가, 서버를 구동하는 디바이스의 CPU, 메모리, 디스크 등에 고장이 일어났을 때 해당된다.
이런 상황들이 발생 할 수 있는 케이스는 전원에 제공이 되지 않는다던가, 과열로 인해서 부품에 문제가 생긴다던가, 그것도 아니라면 심지어 홍수, 지진 등 자연재해로 인한 천재지변으로 센터가 마비될 가능성이 있다.
소프트웨어 문제
코드 내의 버그나 오류로 인해 애플리케이션이 마비되는 경우다.
특정 기능을 호출 시 NullPointerException가 발생해 크래시가 일어난다던가, 메모리 관리를 하지 못하여 OOM(Out Of Memory)가 발생하여 서비스가 중단되는 경우가 있다.
네트워크 문제
네트워크 서비스를 이용하지 못하여 연결이 중단되는 경우다.
인터넷 서비스 제공 업체의 문제로 네트워크 서비스를 제공받지 못한다던가, DDoS 공격으로 인해 네트워크 장비에 과부하가 걸려 서버가 응답을 처리하지 못하는 경우가 포함된다.
운영 문제
새로운 기능이라던가, 수정 등의 이유로 배포가 이루어질 때 중단될 수 있고, 잘못된 설정으로 프로그램에서 요구하는 타겟과 연결을 하지 못할 때도 있다.
이외에도 데이터베이스 서버의 장애로 인해 데이터에 접근할 수 없게 되거나, 스토리지 시스템의 장애로 인해 데이터 접근이 불가능해지는 경우 등등 굉장히 복합적으로 서비스 중단의 문제가 발생할 수 있다.
살짝만 들춰봐도 이만큼인데 하나라도 터지면 서비스에 영향을 줄 수 있는 요소들이다.
개발자 입장에서는 보통 배포 시기에 중단 시기를 겪게 되는데 이 시간 동안을 Downtime이라 표현한다.
무중단에서는 이런 요소들을 할 수 있는 만큼 대비를 해놓는 게 중요한 요소일 것이다.
그렇다면 어떤 식으로 대비를 할 수 있는지 알아보자.
서비스 중단 방지
먼저 배포 이전부터 하드웨어나 네트워크 섹션에서 장애가 일어나도 이를 서비스가 중단되지 않아야 한다.
이러한 아키텍처를 High Availability, HA 아키텍처라고 얘기한다.
한국에서는 고가용성이라고 표현하는 것을 자주 봤다.
고가용성, 말 그대로 가용성이 높다는 것이고 가용성은 “서버와 네트워크, 프로그램 등의 정보 시스템이 정상적으로 사용할 수 있는 정도”를 의미한다.
HA
가능한 오랜 시간 동안 지속적으로 운영되도록 보장하는 HA 인프라 요소들을 소개하겠다.
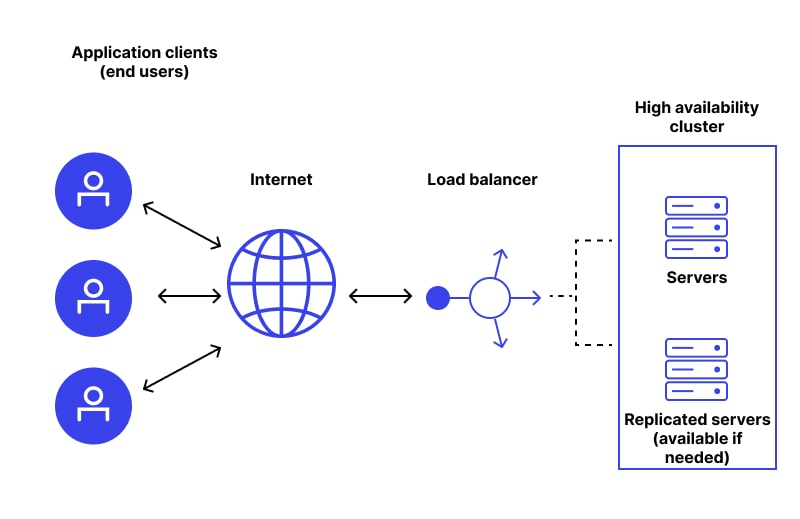 https://www.wallarm.com/what/what-is-high-availability
https://www.wallarm.com/what/what-is-high-availability
서버 이중화
서버를 인스턴스를 여러 개 두는 것을 의미한다.
서버의 인스턴스를 서비스 운영에 사용한다면 이를 Active라고 표현하고, 대기 중인 인스턴스는 Passive 혹은 Stand-by라고 표현한다.
가장 기본적인 구조는 Active - Passive의 형태로 메인 서버의 장애가 발생했을 때 이를 대신할 스페어 서버 정도로 이해하면 된다.
Active 되어 있는 서버를 통해 서비스를 이용하고 있는데, 이 서버에 장애가 발생한다면 Passive 서버가 기존 Active 서버 대신 서비스를 제공하는 역할을 수행한다.
Active에서 Passive로 전이할 때 이를 Fail over라고 표현하며, Active 서버의 Virtual IP를 제거하고 Passive 서버에 제거한 Virtual IP를 할당하기에 클라이언트 입장에서는 이전과 동일하게 서비스를 이용할 수 있다.
참고로 구성된 서버는 Node라는 단위로 불리기도 한다.
목적
서버 이중화를 수행하는 목적은 크게 2가지가 있다.
- 장애 발생 시 빠르게 서비스를 재개.
- 트래픽 분산.
이중화 구조
Active - Active
여러 서버가 동시에 활동하며 트래픽을 분산 처리한다.
Active - Active 구조는 모든 서버가 동시에 요청을 처리하기 때문에 자연스럽게 부하가 분산되기도 하며, 한 서버에 장애가 발생해도 다른 서버가 지속적으로 서비스를 제공할 수 있다.
하지만 데이터 일관성 유지, 구성 및 관리를 위한 비용이 많이 들 수 있다.
Active - Passive
위에서 가장 기본적인 구조라고 말했던 Active - Passive다.
평상시에는 Active 서버가 모든 트래픽을 처리하지만, 장애 발생 시 Passive가 Active의 역할을 수행하게 된다.
이때 Passive는 Active의 상태가 안정적인지 계속해서 확인하다가 문제가 생길 시에 fail over 메커니즘이 동작하여 fail over를 수행한다.
Active에서만 트래픽을 처리하고, 데이터는 실시간으로 복제되기에 일관성을 유지하기 비교적 쉽고, 구성이 간단하여 비용이 많이 들지 않는다.
하지만 Passive로 서버를 계속 가동하고 있기에 리소스를 효율적으로 사용하지 못하며, fail over 시에 시간이 걸릴 수 있다.
필수 요소
데이터 복제.
웬만한 서비스는 공통으로 트래픽이 분산됐을 때 데이터의 정합성이 일치해야 한다.
이는 데이터베이스 이중화를 활용할 수 있다.
데이터베이스의 데이터를 여러 노드에 복제하여 장애시에도 데이터 접근이 가능하도록 말이다.
- Replication
- 기능을 활용하면 데이터를 여러 데이터베이스 인스턴스에 복제하여 실시간으로 동기화한다.
- Master - Slave, Multi - Master 등의 Replication이 있다.
- Clustering
- 여러 데이터베이스 노드를 하나의 클러스터로 구성하여 장애 발생 시 자동으로 다른 노드가 바로 역할을 수행할 수 있는 기능이다.
모니터링
서비스가 잘 동작하고 있는지, 문제가 생겼다면 이를 알려주거나, 관리자가 직접 이를 핸들링하지 않고 자동으로 고가용성이 보장되어야 한다.
추가로 메인 서버뿐만이 아니라 노드에도 문제가 발생했다면 백업 솔루션 추가도 염두 해야 한다.
Load balancing, 로드 밸런싱
이중화와 같은 구조에서 트래픽 분산에 대한 처리가 중요하다.
이런 트래픽을 관리하는 용도로 로드 밸런싱을 사용하는데 함께 알아보자.
일단 용어에서부터 Load Balancing 즉, 부하의 균형을 잡는다는 기술로 추측할 수 있다.
서버 입장에서 부하라 하면 트래픽일 것이고, 이를 균형 잡힌 상태로 유지한다는 건 그런 부하를 위에서 보았던 이중화 인스턴스 등에 나눠준다는 의미다.
주요 기능과 개념
- Traffic Distribution, 트래픽 분산
- 클라이언트 요청을 여러 서버에 분산하여 단일 서버에 과부하가 걸리지 않도록 함.
- Health Checking, Monitoring
- 서버와 애플리케이션 상태를 주기적으로 모니터링하여 장애가 발생한 경로의 트래픽을 차단한다.
- 실시간으로 트래픽과 상태를 모니터링하며, 트래픽 패턴과 성능 데이터를 기록.
- Session Persistence, 세션 유지
- 같은 클라이언트의 요청을 항상 동일한 서버로 전달하여 세션 상태를 유지한다. (Session Stickiness)
- HA, 고가용성
- 서버 장애 시에도 서비스를 지속적으로 제공하기 위해 다른 서버로 트래픽을 재분배.
- 이중화: 로드 밸런서를 이중화하여 단일 장애 지점을 제거.
- 클러스터링: 여러 로드 밸런서를 클러스터링하여 고가용성을 보장.
- Automatic Failover
- 서버 장애 발생 시 자동으로 트래픽을 정상 서버로 전환한다.
- Security, 보안
- DDoS 방어: 분산 서비스 거부(Distributed Denial of Service) 공격 방어 기능을 제공.
- 방화벽 통합: 애플리케이션 방화벽과 통합하여 보안 강화.
- IP 제한: 특정 IP 주소를 차단하거나 허용.
- Tunneling, 터널링
- 출발지와 목적지에서만 사용할 수 있는 프로토콜을 이용하여 패킷을 교환한다.
- 패킷을 감싸는 패킷으로 캡슐화하고, 해당 패킷은 통신 중인 노드에서만 해제할 수 있다.
- NAT(Network Address Translation), 네트워크 주소 변환
- 라우터에서 내부 네트워크와 외부 네트워크 간의 IP주소를 변환하는 기술.
- 여러 개의 호스트로 구분된 인스턴스를 하나의 공인 IP로 접근할 수 있다.
- Dynamic Source Routing protocol(DSR)
- 네트워크 스위치를 거치지 않고 바로 클라이언트의 요청에 응답하는 개념.
- 로드 밸런서가 아닌 client IP로 응답한다.
- 확장성
- 추가 서버를 쉽게 추가하여 시스템의 처리 능력을 확장.
- Scale Out : 쉽게 말해서 서버의 대수를 늘리는 수평 확장.
- Scale Up : 서버의 하드웨어 스펙을 강화하는 수직 확장
로드 밸런서의 유형
먼저 로드 밸런서는 하드웨어로도, 소프트웨어로도 구성할 수 있다.
이에 대해서는 자세히 알아보진 않고 레이어별로 로드 밸런서를 구분해 보겠다.
- L4, Layer 4 Load Balancer
- TCP/UDP의 네트워크 계층에서 작동하며 IP 주소와 포트 번호를 기반으로 트래픽을 분산한다.
- 프로토콜 및 포트 수준에서 패킷 레벨 트래픽을 처리하므로 빠르고 효율적이다.
- L7, Layer 7 Load Balancer
- HTTP/HTTPS의 애플리케이션 계층에서 작동하며 요청 내용을 분석하여 트래픽을 분산한다.
- URL, 헤더, 쿠키, 메시지 등 애플리케이션 레벨의 데이터를 기반으로 분산하니 좀 더 세부적인 트래픽 관리가 가능하다.
부하 분산 방법
- DNS 로드 밸런싱 : DNS에서 여러 IP 주소를 반환하여 해당하는 IP에 트래픽을 분산 처리.
- 애플리케이션 로드 밸런싱 : 애플리케이션 레벨에서 트래픽을 분산 처리.
- 네트워크 레벨 로드 밸런싱 : L4 / L7 로드 밸런싱.
로드 밸런싱 알고리즘
- 라운드 로빈 (Round Robin)
- 작동 방식: 각 서버에 순차적으로 요청을 분산.
- 특징: 구현이 간단하고, 균등하게 분산됨.
- 단점: 서버 성능이 다를 경우 부하가 고르게 분산되지 않을 수 있음.
- 가중 라운드 로빈 (Weighted Round Robin)
- 작동 방식: 각 서버에 가중치를 부여하여 가중치가 높은 서버에 더 많은 요청을 분산.
- 특징: 서버의 성능 차이를 반영하여 분산.
- 단점: 가중치를 설정하는 과정이 필요함.
- 최소 연결 (Least Connections)
- 작동 방식: 현재 연결 수가 가장 적은 서버에 요청을 분산.
- 특징: 부하가 적은 서버에 트래픽을 더 많이 분산.
- 단점: 연결 수를 실시간으로 모니터링해야 함.
- 가중 최소 연결 (Weighted Least Connections)
- 작동 방식: 최소 연결 알고리즘에 가중치를 반영하여 분산.
- 특징: 서버의 성능 차이를 반영하면서도 최소 연결 수를 유지.
- 단점: 가중치 설정과 연결 후 모니터링이 필요함.
- IP 해시 (IP Hash)
- 작동 방식: 클라이언트의 IP 주소를 해싱하여 특정 서버에 요청을 분산.
- 특징: 특정 클라이언트가 동일한 서버에 연결되는 것을 보장.
- 단점: 해시 충돌이나 서버 추가/삭제 시 재분배 필요.
로드 밸런서의 동작 방법
- Bridge Mode / Transparent Mode
- 로드 밸런서가 브릿지 처럼 동작하는 방식.
- 로드 밸런서에서 패킷을 수정하지 않고 바로 전달한다.
- 클라이언트와 서버는 로드 밸런서의 존재를 인식하지 못한다(Transparent, 투명성)
- 과정
- 클라이언트는 IP 주소 192.168.1.10에서 서버 IP 주소 192.168.1.20으로 요청을 보냄.
- 로드 밸런서는 이 요청을 가로채고, 알고리즘에 따라 선택된 백엔드 서버(192.168.1.21)로 요청을 전달.
- 백엔드 서버 192.168.1.21이 응답을 생성하고, 이 응답은 다시 로드 밸런서를 통해 클라이언트 192.168.1.10로 전달.
- 클라이언트와 서버는 서로 직접 통신하는 것처럼 보임.
이외에도 NAT Mode, DSR Mode, TUN Mode 등이 존재한다.
HA에 대해서 자세히 다룬건 위의 요소들 밖에 없지만 백업 및 복구, 모니터링 및 경고 시스템도 함께 구축되어야한다.
Zero-downtime Deployment, 무중단 배포 전략
배포 사이클 중에도 서비스가 중단되지 않는 배포 전략이다.
기본 조건이라 하면 일단 위에서 소개했듯이 HA의 구성을 갖춰야 하니 최소 서버는 2대가 있어야 한다.
Rolling
점진적으로 배포를 진행하는 배포 방식이다.
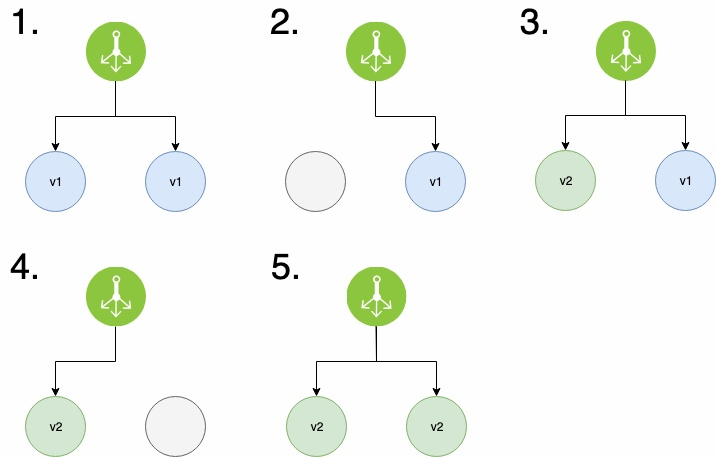 https://onlywis.tistory.com/10
https://onlywis.tistory.com/10
동작 방식
- 분산된 서버 인스턴스 중에서 일부 인스턴스의 트래픽을 끊거나, 서비스를 중단한다.
- 해당 인스턴스에 새로운 버전을 배포한다.
- 테스트를 수행하여 문제가 없다면 해당 인스턴스를 다시 연결한다.
- 새로운 배포가 이루어지지 않은 서버 인스턴스를 끊는다.
- 해당 인스턴스에 새로운 버전을 배포한다.
- 다시 연결한다.
- 모든 서버가 새로운 버전일 될 때까지 위의 과정을 반복한다.
장점
- 점진적 검증 : 각 단계에서 새로운 버전의 안정성을 확인할 수 있고, 문제가 발생하면 이전 단계로 롤백하여 피해를 최소화한다.
- 리소스 효율성: 기존 리소스를 활용하여 새로운 버전을 배포할 수 있기에 별도의 추가 인프라가 필요하지 않다.
단점
- 복잡성 증가 :배포 과정이 복잡해질 수 있고, 단계마다 모니터링과 검증이 필요하다.
- 롤백 어려움 : 새로운 버전에 문제가 발생할 경우, 이미 업데이트된 인스턴스를 다시 원래 버전으로 롤백하는데 번거로울 수 있다.
- 일관성 문제 : 배포 중에 서로 다른 버전의 애플리케이션이 동시에 실행되면서 데이터베이스 스키마 변경 등 버전 간 호환성 문제가 발생할 수 있다.
Blue-Green
두 개의 동일한 서비스 환경을 구축해 놓고 운영 중인 서비스 환경을 Blue, 배포할 환경을 Green이라고 칭한다.
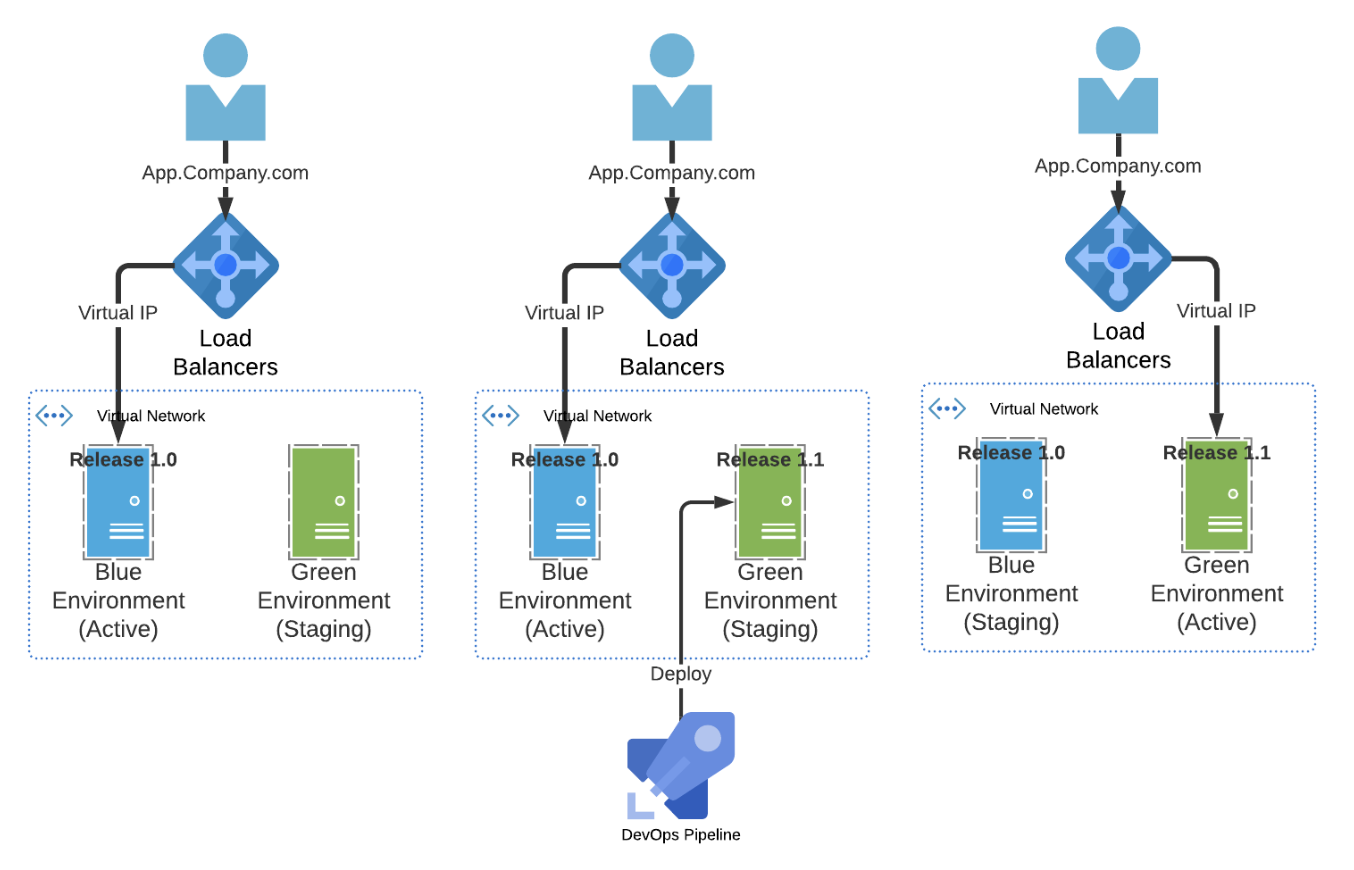 https://blogs.perficient.com/2020/05/14/devsecops-blue-green-deployment-pattern/
https://blogs.perficient.com/2020/05/14/devsecops-blue-green-deployment-pattern/
구성 요소
- Blue : 현재 운영 중인 서비스로 모든 트래픽을 받는 영역이다.
- Green : 새로운 버전을 배포하는 환경으로 Blue와 동일한 설정, 인프라를 가지고 배포와 테스트를 수행하는 영역이다.
동작 방식
- Green에 새로운 버전 배포.
- 배포한 버전이 제대로 동작하는지 테스트.
- 테스트를 성공적으로 마쳤으면 로드 밸런서 또는 DNS를 변경하여 트래픽을 Blue -> Green으로 전환
- Blue는 롤백을 위해서 잠시 유지해 놓아 서비스 중단을 최소화한다.
- Green이 안정적이라면 Blue는 제거되거나 다음 배포를 위해 대기한다.
장점
- 안정성: 새로운 버전을 충분히 테스트한 후에 프로덕션에 반영할 수 있음.
- 빠른 롤백: 문제가 발생하면 즉시 이전 버전으로 롤백할 수 있음.
단점
- 비용 증가: 두 개의 독립적인 환경을 유지해야 하므로 인프라 비용이 증가할 수 있음.
- 복잡성 증가: 환경 간의 설정 및 데이터 동기화가 필요할 수 있어 복잡성이 증가할 수 있음.
Canary
새 버전을 전체 사용자가 아닌 일부 사용자에게만 배포하여 점진적으로 비율을 조정하는 방법이다.
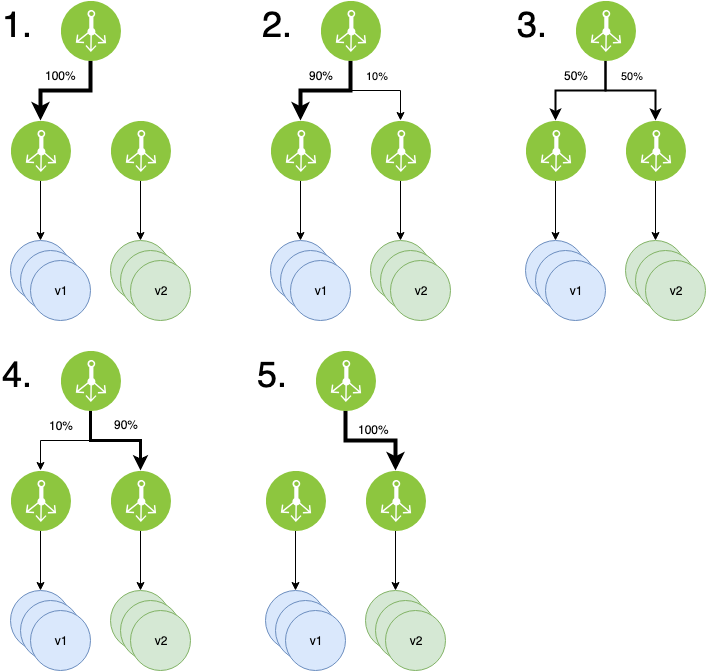 https://onlywis.tistory.com/10
https://onlywis.tistory.com/10
동작 방식
- 새 버전을 소수의 인스턴스에 배포.
- 새로운 배전의 소수 인스턴스는 전체 트래픽의 일부만 처리하도록 설정한다.
- 새로운 버전의 인스턴스에서 발생하는 오류, 성능 등을 모니터링한다.
- 필요시 사용자 피드백을 수집하여 새 버전의 안정성을 평가한다.
- 새 버전이 안정적이라 판단되면 트래픽 처리량을 점진적으로 늘린다.
- 새 버전에 점유율이 100%되면 배포가 완료된다.
A/B 테스트
일부 사용자에게 새로운 버전을 제공하며 기존 버전이 나은지, 새로운 버전이 나은지 의견을 들으며 비교해 보는 실험 방법이다.
장점
- 리스크 최소화 : 새로운 버전의 문제를 초기 단계에서 발견하여 전체 사용자에게 미치는 영향을 최소화할 수 있습니다.
- 복구의 용이성 : 점진적 배포로 인해 문제가 발생하더라도 롤백이 용이하며, 문제 발생 시 소수의 인스턴스만 롤백하면 되기에 신속하게 대응할 수 있다.
- 사용자 피드백 수집 : 실제 사용자 환경에서 새 버전을 테스트하여 사용자 피드백에서부터 개선점을 수집할 수 있다.
단점
- 복잡성 증가 : 트래픽 점유율 핸들링, 사용자 피드백 수집 등으로 배포 과정이 복잡해지고, 각 단계에서 모니터링과 검증을 수행해야 한다.
- 리소스 필요 : 새 버전과 이전 버전을 동시에 운영해야 하므로 추가 리소스가 필요하다.
- 네트워크 설정 : 로드 밸런서나 프록시 서버에서 트래픽을 특정 인스턴스로 분배하는 설정이 필요하다.
위와 같은 무중단 배포 전략은 k8s, Istio, AWS 등에서도 옵션으로 제공하기에 간단하게 구현할 수 있다.
세션 복구 전략
무중단이라 하더라도 Client와 Server 간에 Session 단절이 발생할 수 있다.
이럴 때, 빠르게 다시 세션을 연결해 줘야 Client의 불편을 최소화할 수 있다.
Session Persistence, 세션 지속성
로드 밸런스 파트에서 살짝 들었던 Session Stickiness라는 단어가 있다.
이는 로드 밸런서가 클라이언트의 세션을 계속해서 동일한 서버에 연결되도록 보장하는 것을 의미하는데, 클라이언트의 IP나 쿠키 등을 이용하여 세션 정보가 일관되게 유지하는 방법이다.
세션 단절로 문제가 일어났을 때 동일한 정보로 다시 연결을 수행하기 위해 필요한 요소라 할 수 있다.
Session Clustering, 세션 클러스터링
애플리케이션 인스턴스 간 세션 정보를 공유하는 것을 의미한다.
하나의 서버가 중단되더라도 다른 서버가 동일한 세션 정보를 가지고 재연결할 수 있다.
Redis나, Memcached 등으로 분산 캐싱 처리하거나 데이터베이스를 이용하여 세션 상태를 공유하거나, 클러스터링 기능을 이용하여 세션 복제(Session Replication)를 활용할 수 있다.
Automatic Reconnect and Retry, 자동 재연결 및 재시도
웹 소켓이라던가, HTTP/HTTPS 등의 커넥션은 Close 이벤트에서 연결이 끊긴 상태 값 code 값으로 핸들링하거나, wasClean 속성을 이용하여 비정상적인 close를 인식할 수 있다.
만약 비정상적인 종료라면 자동으로 재연결을 시도할 수 있다.
서버에서 재연결을 수행할 수도 있고, 클라이언트에서 수행(Stateless Sessions)할 수 있다.
이때 계속해서 재연결을 요청하면 부하가 걸릴 수 있으니, Exponential Backoff 전략을 이용하여 재연결 시도간 시간 간격을 점진적으로 늘려야 한다.
어우 길다 길어…
Ref.
https://pythontoomuchinformation.tistory.com/475