
[Database] Database Index - 적용 part 1.
[Database] Database Index - 기본 개념 의 포스트에서 인덱스의 종류와 기본적인 개념을 알아봤다.
그렇다면 실제로 데이터베이스에 적용해보면서 얼마나 큰 성능 차이가 있는지 알아보는 시간을 가져보자.
참고로 이 포스트는 PostgreSQL을 기준으로 진행하기에 데이터 타입 등 차이점이 존재할 수 있다.
Index 적용 기준
인덱스를 적용하기 전 어떤 컬럼 혹은 테이블에 인덱스를 적용하면 적절히 성능을 개선시킬 수 있는지 간단히 알아보자.
Cardinality가 높은 컬럼
높은 카디널리티 → 검색 결과의 데이터 수가 적다 → 인덱스 효율이 높다
Cardinality, 카디널리티란 한 컬럼에서 중복되지 않는 데이터의 개수를 의미한다.
- 높은 카디널리티
- 대부분의 값이 Unique한 컬럼
- 주민등록번호, 이메일…
- 성능 개선 효과가 큼
- 낮은 카디널리티
- 대부분의 값이 중복되는 컬럼
- 성별, 지역코드…
- 성능 개선 효과가 낮음
높은 카디널리티는 중복되는 값이 적기에 검색 결과의 데이터 수가 적어진다.
데이터가 적다는 것은 검색 범위를 좁히는 데 유리하기 때문에 결국, 카디널리티가 높은 컬럼에 인덱스를 적용시킨다면 조회 성능이 향상하게 된다.
카디널리티 확인
SELECT 컬럼명, COUNT(DISTINCT 컬럼명) AS 카디널리티
FROM 테이블령;
업데이트가 적은 컬럼
변경이 적은 컬럼 → 인덱스 유지 비용 감소
인덱스는 조회 성능을 개선하는 대신 삽입/수정/삭제 시에는 인덱스 재구성 비용이 커지기에 성능 저하를 일으킬 수 있다.
WHERE 조건에 자주 사용되는 컬럼
WHERE 조건 컬럼 → 인덱스 탐색 범위 감소
자주 WHERE 절에 사용하며 필터링하는 컬럼에 인덱싱하면 조회 성능이 향상된다.
JOIN, ORDER BY에 사용되는 컬럼
JOIN 키 또는 정렬 기준 컬럼 → 성능 최적화
두 테이블을 결합하는 기준인 JOIN 컬럼에 적용 시 빠른 데이터 결합이 가능하며, 정렬 시 사용되는 ORDER BY는 불필요한 정렬을 줄인다.
데이터의 크기가 큰 테이블
데이터가 많은 테이블 → 인덱스가 더 큰 효과
테이블 데이터가 클수록 효율은 극대화된다.
Primary Index
테이블 내에서 유일을 보장해주는 컬럼에 제공하는 인덱스다.
보통은 SERIAL (AUTO INCREASE) 과 같은 자동 증가 값과 같은 ID 컬럼에 부여한다.
테이블 생성
샘플용 테이블을 만들어보자.
CREATE TABLE 근무자(
id SERIAL PRIMARY KEY,
이름 VARCHAR(100) NOT NULL,
이메일 VARCHAR(100) UNIQUE NOT NULL,
부서 VARCHAR(100),
등록일 DATE DEFAULT now()
);
Primary Key / Primary Index / Clustered Index
주목할 부분은 id 컬럼이다.
SERIAL로 테이블 내에서 유일한 자동 증가값을 지정해주고, 이를 PRIMARY KEY를 설정 했다.
일반적으로 PRIMARY KEY를 설정하면 해당 컬럼은 Primary Index 로 설정되는 경우가 많다.
PRIMARY KEY를 기준으로 정렬되어 자동 저장되기 때문에 일종의 Clustered Index로 취급된다.
그렇다고 Primary Index가 언제나 Clustered Index라는 것은 아니다.
Primary Index == Clustered Index
Primary Key를 설정했을 때 데이터베이스가 자동으로 해당 컬럼에 대해 Clustered Index를 생성한다면, Primary Index는 Clustered Index와 동일한 역할을 수행하게 된다.
이 상황에서는 두 용어가 비슷하게 사용될 수 있다.
id 컬럼은 Primary Key이며, 이로 인해 기본적으로 Clustered Index가 설정되었다면 id 컬럼에 대한 Primary Index와 Clustered Index가 같은 역할을 수행한다.
Primary Index != Clustered Index
반드시 Primary Key에만 Clustered Index를 적용할 필요는 없다.
다른 컬럼에 대해 Clustered Index를 수동으로 설정할 수 있으며, 이 경우 Primary Key는 Primary Index로서 유일성을 보장하지만, Clustered Index는 다른 컬럼에 대해 데이터 정렬과 조회 성능을 향상시키는 역할을 하게 된다.
등록일 컬럼에 대해 Clustered Index를 따로 생성한다면, id 컬럼은 Primary Index로 남고, 등록일 컬럼은 Clustered Index로 설정되어 두 인덱스의 역할이 달라진다.
샘플 데이터 및 조회
조회 성능을 비교해보기 위해서 넉넉하게 1,000,000개의 데이터를 넣어보자.
DO $$
BEGIN
FOR i IN 1..1000000 LOOP
INSERT INTO 근무자 (이름, 이메일, 부서)
VALUES (
'직원' || i,
'employee' || i || '@company.com',
CASE
WHEN i % 4 = 0 THEN '인사'
WHEN i % 4 = 1 THEN '디자인'
WHEN i % 4 = 2 THEN '영업'
ELSE '개발'
END
);
END LOOP;
END $$;
데이터 삽입 후
SELECT * FROM 근무자;
를 실행하면 아래와 같이 추가된 데이터가 조회될 것이다.
| id | 이름 | 이메일 | 부서 | 등록일 |
|---|---|---|---|---|
| 1 | 직원1 | employee1@company.com | 디자인 | 2024-12-05 |
| 2 | 직원2 | employee2@company.com | 영업 | 2024-12-05 |
| 3 | 직원3 | employee3@company.com | 개발 | 2024-12-05 |
| 4 | 직원4 | employee4@company.com | 인사 | 2024-12-05 |
| … | … | … | … | … |
| 99998 | 직원99998 | employee99998@company.com | 영업 | 2024-12-05 |
| 99999 | 직원99999 | employee99999@company.com | 개발 | 2024-12-05 |
| 100000 | 직원100000 | employee100000@company.com | 인사 | 2024-12-05 |
Row Limit 해제 시 Full Scan에
의 시간이 소모됐다.
이는 쿼리 실행 시간과는 다른 의미를 가진다.
EXPLAIN ANALYZE
PostgreSQL을 기준으로 조회 성능을 측정하기 위해
EXPLAIN ANALYZE
SELECT * FROM 근무자;
의 명령어를 수행할 수 있다.
참고로 쿼리는 매번 실행할 때 마다 같은 값을 가지진 않는다.
| QUERY PLAN |
|---|
| Seq Scan on “근무자” (cost=0.00..31211.00 rows=1000000 width=53) (actual time=0.032..82.086 rows=1000000 loops=1) |
| Planning Time: 0.067 ms |
| Execution Time: 111.773 ms |
EXPLAIN
쿼리 실행 계획을 보여준다.
쿼리를 어떻게 실행할 것인지에 대한 각종 정보가 포함되어 있으며, 테이블 스캔 방식, 인덱스 사용 여부 등을 확인할 수 있다.
| Seq Scan on “근무자” (cost=0.00..31211.00 rows=1000000 width=53) (actual time=0.032..82.086 rows=1000000 loops=1) |
ANALYZE
실제로 쿼리를 실행하면서 실행 시간을 측정하여 추가적인 성능 데이터를 제공한다.
EXPLAIN만 사용하면 실행 계획만 보여줄 뿐 쿼리를 실제로 실행하지는 않지만, ANALYZE를 추가하면 쿼리를 실제로 실행하면서 실행 통계 정보를 수집한다.
| Planning Time: 0.067 ms |
|---|
| Execution Time: 111.773 ms |
좀 더 상세하게 설명하자면
Seq Scan on “근무자”
Sequential Scan 즉, 근무자 테이블을 순차적으로 스캔 했다는 의미다.
이는 테이블에 인덱스가 없을 때 전체 데이터를 읽는 경우다.
(cost=0.00..31211.00 rows=1000000 width=53)
예상되는 비용(리소스 소모), 행의 수와 사이즈를 의미한다.
- cost=0.00..31211.00 시작(초기화) 비용은 0.00, 완료(전체) 비용은 31211.00이 소모될 것으로 예상된다.(상대적인 수치)
- rows=1000000 쿼리를 실행하면 100,000 개의 행이 조회될 것으로 예상한다.
- width=53 각 행이 53바이트 정도로 예상한다.
(actual time=0.032..82.086 rows=1000000 loops=1)
실제로 소모한 비용, 조회된 행의 수, 반복 횟수.
- actual time=0.032..82.086 실제로 실행될 때 0.032ms가 걸렸고, 완료되는데 총 82.086ms가 걸렸다.
- rows=100000 실제로 100,000건의 행이 조회됐다.
- loops=1 한 번의 스캔으로 데이터를 모두 가져왔다.
Planning Time: 0.067 ms
쿼리를 실행하기 위해 계획을 수립하는데 걸린 시간.
Execution Time: 111.773 ms
데이터 풀 스캔 및 반환에 걸린 총 시간을 의미한다.
SELECT … WHERE id
그렇다면 위와 같이 풀스캔이 아닌 조건절을 통해 조회해보자.
Primary Key를 지정해 Primary Index로 지정된 id를 기준으로 조회해보겠다.
EXPLAIN ANALYZE
SELECT * FROM 근무자 WHERE id = 1000000;
| QUERY PLAN |
|---|
| Index Scan using “근무자_pkey” on “근무자” (cost=0.42..8.44 rows=1 width=53) (actual time=0.029..0.031 rows=1 loops=1) |
| Index Cond: (id = 1000000) |
| Planning Time: 0.094 ms |
| Execution Time: 0.052 ms |
와 같이 짧은 시간이 걸렸다.
여기서 의문을 가질 수 있는게 1,000,000를 모두 가져오는게 아니라 1건만 가져오니깐 시간이 짧은게 아니냐고 생각할 수 있겠다.
그럼 인덱스 스캔이 아닌 방식으로 수행한다면?
EXPLAIN ANALYSE
SELECT * FROM 근무자 WHERE id::TEXT = '1000000';
id를 TEXT로 캐스팅하여 조회하여 인덱스 조회가 되지 않도록 해봤다.
| QUERY PLAN |
|---|
| Gather (cost=1000.00..30002.67 rows=5000 width=53) (actual time=24.049..82.711 rows=1 loops=1) |
| Workers Planned: 2 |
| Workers Launched: 2 |
| -> Parallel Seq Scan on “근무자” (cost=0.00..28502.67 rows=2083 width=53) (actual time=52.066..70.823 rows=0 loops=3) |
| Filter: ((id)::text = ‘1000000’::text) |
| Rows Removed by Filter: 333333 |
| Planning Time: 0.177 ms |
| Execution Time: 82.756 ms |
간단히 설명하자면
Gather: 병렬 작업Workers Planned: 2/Workers Launched: 2: 병렬로 수행 했기에 2명의 워커가 작업을 계획하고 실행.Parallel Seq Scan on "근무자": 병렬 순차 스캔으로 각 워커가 테이블의 일부를 동시에 스캔Filter: ((id)::text = '1000000'::text): 조건에 맞는 행 필터링Rows Removed by Filter: 333333: 필터링으로 제거된 행 수
풀 스캔보단 오래 걸리지 않았지만 인덱스와 비교했을 때 큰 성능 차이를 보여준다.
Secondary Index
Primary Key가 아닌 컬럼에 인덱스를 적용하는 보조 인덱스다.
보조 인덱스는 포인터를 통해 조회하기에 별도의 인덱스 테이블이 생성된다.(Non-Clustered Index)
별도의 저장 공간을 차지하는 만큼 불필요하게 많은 인덱스를 생성하지 않도록 주의 해야한다.
테이블 생성
테이블은 위에서 생성한 예시를 그대로 사용하겠다.
먼저 보조 인덱스를 적용하기 전에 쿼리 성능을 확인해보자.
SELECT * FROM 근무자 WHERE 부서 = '개발';
| QUERY PLAN |
|---|
| Seq Scan on “근무자” (cost=0.00..33711.00 rows=251500 width=53) (actual time=0.025..97.349 rows=250000 loops=1) |
| Filter: ((“부서”)::text = ‘개발’::text) |
| Rows Removed by Filter: 750000 |
| Planning Time: 0.105 ms |
| Execution Time: 104.104 ms |
Seq Scan 으로 인덱스가 적용 안된 상태로 조회를 하고 성능도 뛰어나지 않은 것을 확인할 수 있다.
인덱스 적용
이번엔 인덱스를 적용 시켜보자.
CREATE INDEX idx_부서 ON 근무자(부서);
QUERY PLAN
이후 이전과 같이 조회 쿼리를 실행하면
| QUERY PLAN |
|---|
| Bitmap Heap Scan on “근무자” (cost=2809.55..27164.30 rows=251500 width=53) (actual time=8.669..46.490 rows=250000 loops=1) |
| Recheck Cond: ((“부서”)::text = ‘개발’::text) |
| Heap Blocks: exact=10606 |
| -> Bitmap Index Scan on “idx_부서” (cost=0.00..2746.68 rows=251500 width=0) (actual time=7.087..7.087 rows=250000 loops=1) |
| Index Cond: ((“부서”)::text = ‘개발’::text) |
| Planning Time: 0.095 ms |
| Execution Time: 55.498 ms |
와 같이 뜨는 것을 확인할 수 있다.
하지만 기본 인덱스의 Index Scan과 다르게 Bitmap Heap Scan의 스캔을 한 것을 확인할 수 있다.
Bitmap Heap Scan
대량의 데이터 조회 시 효율적인 조회 방식으로 특정 조건을 만족하는 데이터에 대해 블록 단위로 읽어오는 방식이다.
먼저 인덱스에서 조건에 맞는 데이터를 먼저 찾고, 해당 데이터를 실제 테이블(Heap)에서 읽어온다.
조건을 만족하는 데이터가 많은 경우 Bitmap Index Scan은 블록 단위로 작업하기 때문에 Random I/O를 줄이고, Sequential I/O를 증가 시켜 성능을 개선 시킨다.
즉, 인덱스를 활용하되, 효율적인 데이터 조회를 위해 PostgreSql에서 최적화된 조회 방식인 Bitmap 방식을 활용한 것이다.
Recheck Cond
조건(Condition)을 다시 체크(Recheck)한 것을 의미한다.
인덱스로 찾은 결과가 실제 테이블 데이터와 비교하면서 조건을 충족하는지 한 번 더 확인하는 과정을 가진다.
Heap Blocks: exact=10606
PostgreSQL이 테이블에서 데이터를 읽기 위해 접근한 블록 수를 의미한다.
하지만 실제로 조회된 행은 250,000인데 (actual ... rows=250000 ... ) 왜 블록은 10,606 개를 조회 했을까?
Heap
테이블의 정보를 저장하는 파일을 의미한다.
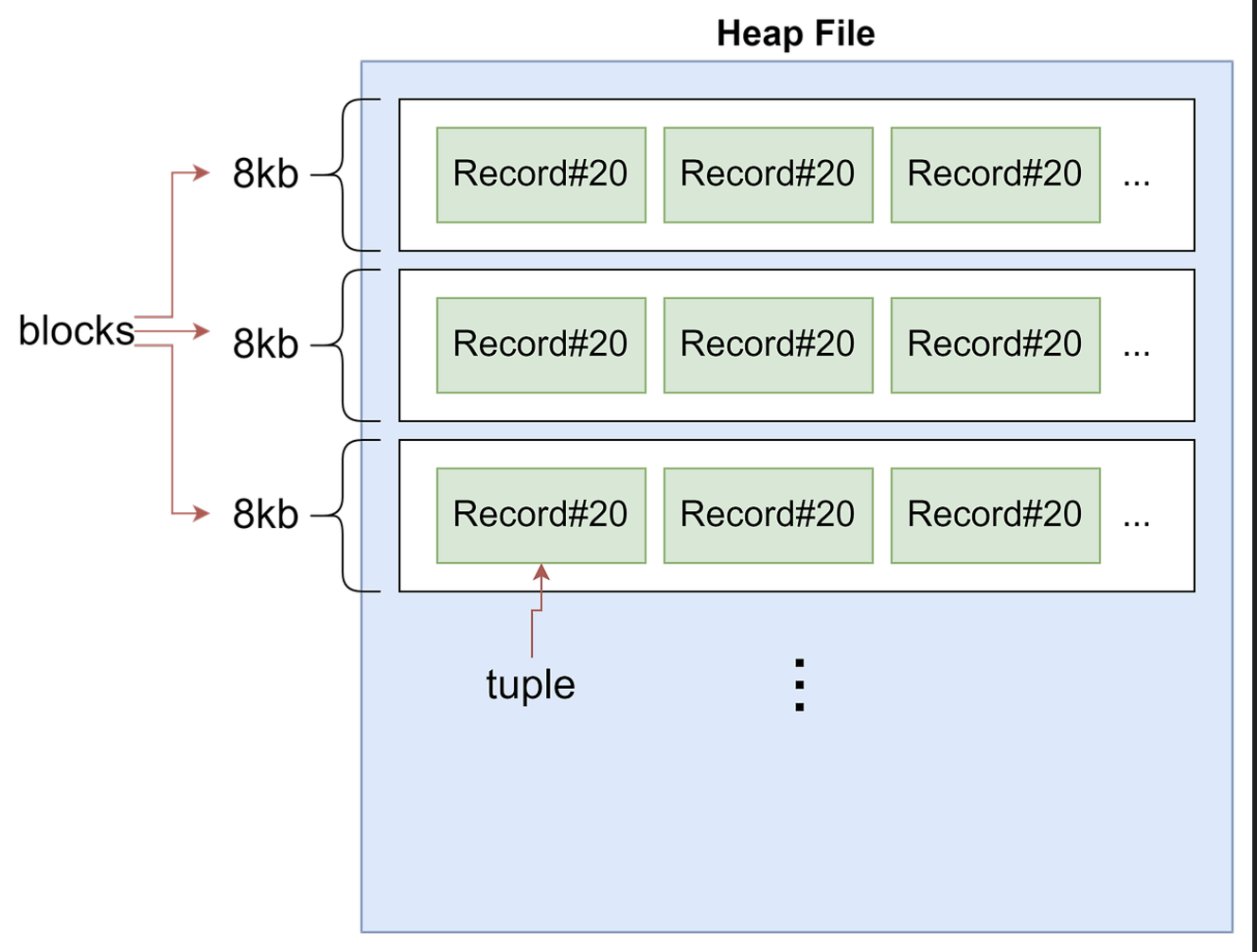
https://2jun0.tistory.com/52
하나의 Heap에는 여러개의 블록들로 이루어지는데 각 블록의 크기는 보통 8KB로 구성되며, 한 블록에는 여러 행이 저장될 수 있다.
Block
PostgreSQL은 데이터를 저장할 때 블록이라는 단위로 저장한다.

https://2jun0.tistory.com/52
각 행이 평균적으로 32바이트라고 가정하면 250000 / 256 ≅ 9766 이다.
크기 계산
저장된 데이터 행 하나를 계산해보자
CREATE TABLE 근무자
(
id SERIAL PRIMARY KEY, -- 4바이트
이름 VARCHAR(100) NOT NULL, -- 가변
이메일 VARCHAR(100) NOT NULL UNIQUE, -- 가변
부서 VARCHAR(100), -- 가변
등록일 DATE DEFAULT NOW() -- 4바이트
);
| id | 이름 | 이메일 | 부서 | 등록일 |
|---|---|---|---|---|
| 3 | 직원3 | employee3@company.com | 개발 | 2024-12-07 |
- id : 4바이트 (고정)
- 이름 : 6바이트(한글 “직원”) + 1바이트(숫자 “3”) + 1바이트(길이 정보) = 8바이트
- 이메일 : 21바이트+ 1바이트(길이 정보) = 22바이트
- 부서 : 6바이트(한글 “개발”) + 1바이트(길이 정보) = 7byte
- 등록일 : 4바이트(고정)
이렇게 까지 계산하면 45바이트 가 나온다.(아마?)
하지만 PostgreSQL은 각 행에 대해 Overhead(추가 메타 데이터)를 저장한다.
- 행 헤더(Tuple Header): 23바이트
- xmin, xmax : 트랜잭션 ID
- NULL 비트맵: NULL 값이 없더라도 최소 1바이트
- 총 오버헤드: 23 + 1 = 24바이트
INTEGER나 DATE는 항상 일정한 크기를 가지지만 VARCHAR, TEXT 와 같은 데이터 타입은 가변적이라 들어가는 값에 따라 한 행의 크기는 일정하지 않을 수 있다.
즉, 250,000 개의 행은 10,606 개의 블록에 분산 저장되어 있다는 것을 의미하고 반대로 250,000 개의 행을 읽기 위해 10,606 개의 블록을 조회 했다는 뜻이된다.
Bitmap Index Scan on “idx_부서”
이제 본격적으로 보조 인덱스를 스캔하는 부분이 나온다.
위에서 생성(설정)한
CREATE INDEX idx_부서 ON 근무자(부서);
인덱스를 기준으로 조회하는 것을 볼 수 있다.(on “idx_부서”)
Bitmap Index Scan으로 조건에 만족하는 행 수, 위치 정보(페이지)의 위치 정보를 비트맵으로 반환하여 Bitmap Heap Scan 에서 필요한 데이터가 있는 블록만 읽어 성능을 최적화한다.
witdh=0
예상되는 데이터에 길이가 0으로 나오는 것에 의아할 수 있다.
이는 비트맵 인덱스 스캔 시 데이터가 아닌 데이터의 위치 정보를 통해 데이터를 읽어오기 때문이다.
Index Cond: ((“부서”)::text = ‘개발’::text)
인덱스의 조건을 의미한다.
::text 를 통해 캐스팅을 진행하였는데, 이는 조건에 부함하는 완벽한 일치의 데이터를 찾기 위한 과정이라 할 수 있다.
현재 부서 컬럼은 VARCHAR(100)인데 우리가 조건으로 줬던 ‘개발’은 text 타입으로 부서 컬럼을 캐스팅 한 것이다.
캐스팅으로 인하여 미미한 성능 차이가 있지만, 이를 개선하고 싶다면 컬럼의 타입과 조건 데이터의 타입을 일치 시켜주면 된다.
Unique Index
무결성을 유지하고 특정 컬럼 값이 중복되지 않도록 보장(강제)하는 인덱스다.
Index가 웬만하면 삽입, 수정의 성능을 보장 못 해주긴 하지만 특히 Unique Index는 중복 검사를 추가적으로 수행하기에 다른 인덱스에 비해 비용이 약간 더 들 수 있다.
동일한 컬럼에 Primary Index와 Unique Index를 설정한다면 불필요한 저장 공간과 성능 저하를 일으킬 수 있으니 주의하자.
Primary Index / Unique Index
| Primary Index | Unique Index | |
|---|---|---|
| 유일성 | 반드시 유일한 값 | 중복되지 않는 유일한 값 |
| NULL 값 허용 | X | O (하나의 NULL 값만 허용) |
| 자동 생성 | PRIMARY KEY 설정 시 | UNIQUE 제약 조건 설정 시 |
| 설정 개수 | 테이블당 하나 | 여러 컬럼 |
NULL
PostgreSQL 에서 NULL 값은 ‘값이 없다’로 취급된다.
불명확하거나 정의되지 않은 상태로 NULL = NULL은 항상 FALSE로 NULL은 서로 비교할 수 없다.
간단하게 표현하자면 UNIQUE INDEX는 중복값을 허용하지 않는데 이미 NULL인 행이 있는데 또 NULL을 넣으면 중복 된다.(이해하기 쉽게 하기 위해 극단적인 예시를…)
비교를 할 수 없는 값이 들어가면서 데이터 무결성 유지가 힘들어 진다는 것이다.
혹여 여러 개의 NULL을 입력하고 싶다면
CREATE UNIQUE INDEX idx_이메일 ON 근무자(이메일)
WHERE 이메일 IS NOT NULL;
로 Partial Index를 적용할 수는 있다.
인덱스 생성
UNIQUE 제약 조건과 연관됐는데, 위에서 설정했다시피 우리는 이메일 컬럼에 UNIQUE를 설정했었다.
UNIQUE 자체는 제약 조건이지만 인덱스를 자동으로 생성해준다.
수동으로 설정하기 위해서는
CREATE UNIQUE INDEX idx_이메일 ON 근무자(이메일)
와 같이 설정 가능하다.
참고로 테이블에 적용된 인덱스를 확인하기 위해서는
psql
d 근무자;
PostgreSQL 표준
SELECT
indexname AS index_name,
indexdef AS index_definition
FROM pg_indexes
WHERE tablename = '근무자';
로 조회가 가능하다.
| index_name | index_definition |
|---|---|
| 근무자_pkey | CREATE UNIQUE INDEX “근무자_pkey” ON public.”근무자” USING btree (id) |
| 근무자_이메일_key | CREATE UNIQUE INDEX “근무자_이메일_key” ON public.”근무자” USING btree (“이메일”) |
| idx_부서 | CREATE INDEX “idx_부서” ON public.”근무자” USING btree (“부서”) |
데이터 조회
SELECT
EXPLAIN ANALYSE
SELECT * FROM 근무자 WHERE 이메일 = 'employee3@company.com';
| QUERY PLAN |
|---|
| Index Scan using “근무자_이메일_key” on “근무자” (cost=0.42..8.44 rows=1 width=53) (actual time=1.659..1.661 rows=1 loops=1) |
| Index Cond: ((“이메일”)::text = ‘employee3@company.com’::text) |
| Planning Time: 0.254 ms |
| Execution Time: 1.711 ms |
위에서 설명한 것 처럼 인덱스 조회와 추가적인 동작이 수행된다.
이번 포스트에서는 Primary, Secondary, Unique Index를 적용해보았다.
다음 포스트는 Composite, Full-Text Index를 적용 시켜보자.
Ref.