
[Database] NoSQL 데이터 모델링 서론 및 절차.
NoSQL 모델링 서론
NoSQL은 RDBMS와 같은 DBMS 이지만 데이터 저장을 위한 Put/Get 만을 지원하며 RDBMS에서 익숙하게 사용해왔던 ORDER, JOIN, GROUP, INDEX 등의 기능들을 지원하지 않는다.
(MongoDB, CouchDB와 같은 Document Store 기반의 NoSQL은 기능을 제공하기도한다.)
복잡한 쿼리를 사용해 원하는 결과를 도출하는 RDBMS와 달리 NoSQL은 제한이 많기에 설계도 다르게 진행된다.
NoSQL은 쿼리 결과 지향 모델링
RDBMS는 [도메인 분석 -> 관계 형성 -> 테이블 추출 -> 쿼리 구현] 의 과정을 거쳤다면
NoSQL은 [도메인 분석 -> 쿼리 결과 구상 -> 테이블 추출] 의 순서로 테이블을 디자인한다.
어떤 결과가 필요한지 구상한 후에 결과를 얻기 위한 테이블을 디자인해야한다.
비정규화
데이터 일관성을 위해 중복 제거와 같은 방법으로 정규화를 강제했던 RDBMS와 다르게 NoSQL은 쿼리의 효율성을 위해서 정규화 과정을 거치지 않고 오히려 중복 데이터를 저장하는 식의 비정규화를 고려해야한다.
NoSQL 모델링 절차
1. 도메인 모델 파악.
RDBMS과 다르게 NoSQL에서는 ERD를 작성하여 도식화된 도메인 구성을 하지 않고 바로 애플리케이션 관점으로 넘어가는 경우도 있다.
하지만 제대로된 도메인 모델 분석 없이는 제대로된 데이터 모델을 설계할 수 없으니 도메인 분석을 실시하는 것이 중요하다.
현재 사이드 프로젝트로 방명록 시스템을 개발을 기획하고 있는데 이를 이용하여 도메인 모델을 작성해보자.
- 방명록 시스템은 방명록 카드 등록 시
- 제목
- 내용
- 작성자
- 인증코드
- 카드 색상 정보
의 내용을 입력할 수 있다.
- 삭제와 수정의 기능을 수행하기 위해 인증 코드를 사용한다.
이를 엔티티로 표현해보자면.
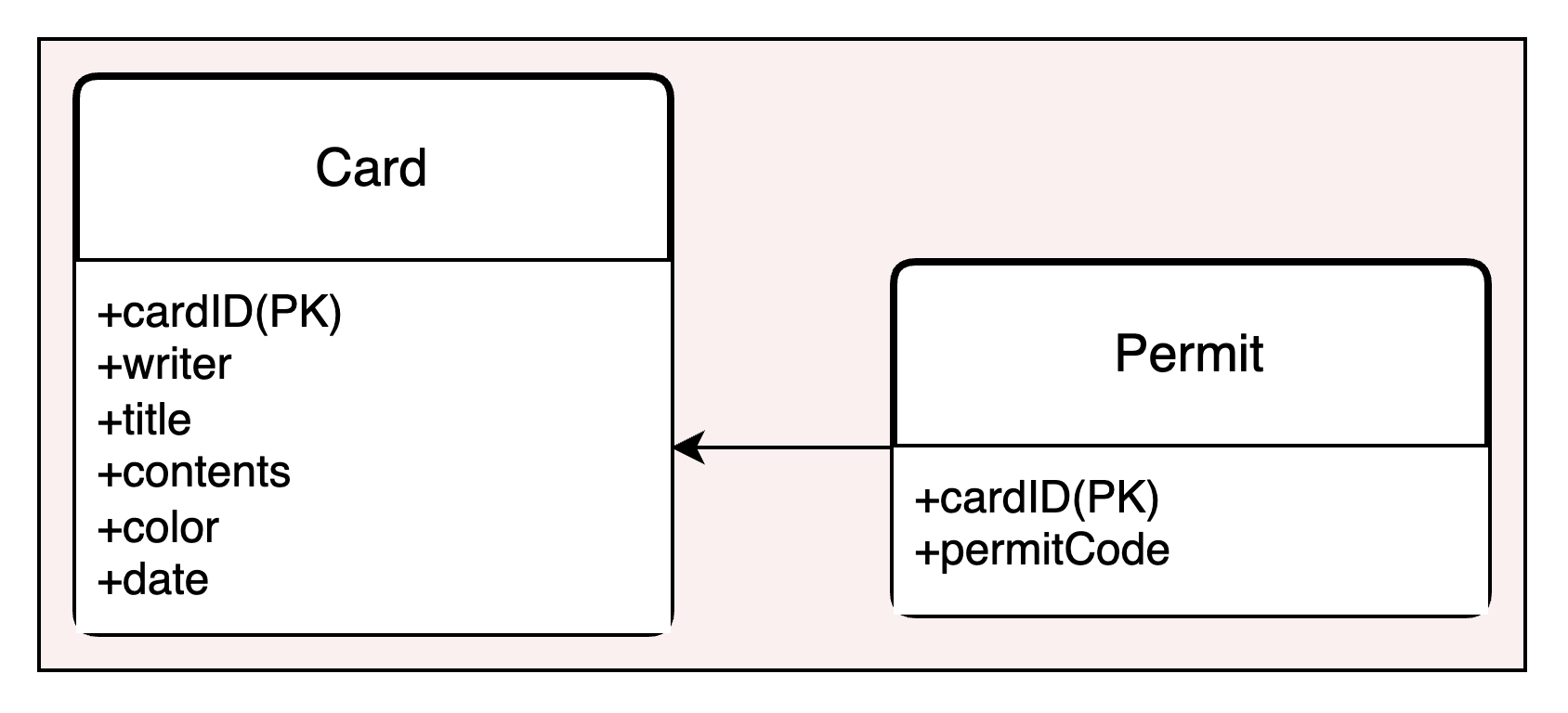
와 같을 것이다. (Permit 엔티티를 따로 뺄 필요는 없었지만 너무 단순한 것 같아서 Permit을 분리해봤다…)
2. 쿼리 결과 디자인.
어떤 데이터를 가져와 어떤식으로 표시할 것인지 정하는 중요한 단계이다.

위와 같은 형태로 출력을 하고싶다.
이를 쿼리로 불러오기 위해서는 기본적으로는
SELECT cardID, title, contents, writer, color,date FROM Card
와 같이 작성하며, 작성자로 검색한다면
SELECT cardID, title,contents, writer, color,date FROM Card WHERE = {wtiter}
로 작성할 수 있을 것이다.
수정/삭제를 위한 권한 확인을 위한 인증코드를 가져오기 위해서
SELECT permitCode FROM Permit where cardID = {cardID}
와 같은 방식으로 작성할 수 있을 것이다.
추가로 이를 하나로 출력하자면
SELECT
ca.cardID, ca.title, ca.contents, ca.writer, ca.color, ca.date, per.permitCode
FROM
Card ca, Permit per
WHERE
ca.cardID = per.cardID
와 같을 것이다.(작성자로 검색하는 건 제외했다.)
출력되는 데이터 테이블은

와 같을 것이다.
3. 패턴 기반 모델링.
데이터 출력 디자인을 기반으로 NoSQL에 정의될 데이터 모델링을 한다. 기본적으로 Sort, Group, Join을 배제하고 put/get으로만 NoSQL내 테이블에 재정의 한다.
이런 한계를 극복하기 위해 Denormarlization, Aggregation, Application Side Join 등이 있지만, 핵심 기법인 Denormalization 패턴을 기반으로 저장해보자.
Denormalization을 상세하게 설명하자면
Denormalization
같은 데이터를 중복해서 저장하는 방식으로 JOIN을 없애고, 데이터를 읽어오는 횟수를 줄일 수 있다.
기본적으로 NoSQL은 JOIN을 지원하지 않기에 테이블간 JOIN을 구현하기 위해 테이블에서 각각의 데이터를 읽어와야하기에 과도한 I/O가 발생한다.
위에 작성한 쿼리 결과 디자인 중
SELECT
ca.cardID, ca.title, ca.contents, ca.writer, ca.color, ca.date, per.permitCode
FROM
Card ca, Permit per
WHERE
ca.cardID = per.cardID
를 예시로 들다면 2개의 테이블을 JOIN 하였는데 이를 걷어 낸다면
SELECT $cardID, title, contents, writer, color, date
SELECT permitCode WHERE cardID = $cardID
와 같이 2번의 SELECT를 수행해야한다.
지금도 비효율적이지만 JOIN이 많다면 상당히 부하가 많이갈 것이다.
이를 개선하기위해 JOIN 되어있는 테이블을 추가로 만들어 그 테이블을 Get 하면 된다.
방법은 key에 해당하는 데이터를 ‘:’(deliminator)로 하나로 묶은 Key로 만들어서 NoSQL 스타일로 디자인하자.
- JOIN 제거.
- Sorting.(Enumerable Keys)
- Grouping.(Composite Key)
을 가능 하게 만든다.

(필자가 작성한 구조가 너무 간단해서 오히려 이해하기 어렵다…)
4. 최적화를 위한 필요 기능 구상
변경이 많지 않고, 필수 항목이 아닌 Attribute는 Value에 Document Store와 같은 데이터 타입 사용을 고려할 수 도 있다. 이를 통해 RDBMS의 Index의 개념과 같은 Secondary Index를 구현해 Oedered Key 형태로 Sorting이 가능할 것이다.
하지만 NoSQL 시스템에 따라 특성이 다르고 그마다 최적화가 이뤄지는 설계가 각자 다를 수 있다. 부가 기능을 통해 최적화를 이룩하고 싶다면 내부 구조를 분석, 테스트를 하면서 개발을 해야한다…
5. 적절한 NoSQL 선정.
NoSQL의 구조 및 특성을 분석하여 설계한 구조에 적합한 NoSQL을 선정해야한다. 부하 테스트, 안정성, 확장성 테스트를 거쳐야하며, 경우에 따라서는 하나 이상의 NoSQL을 사용할 수도 있다.
6. 채택한 NoSQL의 특성에 맞는 최적화/하드웨어 디자인.
최종적으로 선정한 NoSQL에 맞게 데이터 모델을 최적화하고, 애플리케이션 인터페이스, 구동 환경 등을 디자인해야한다.