
[DB] Redis의 개념
기업들의 서버 기술 스택에서 자주 보이는 Redis, Redis는 무엇이고 왜 쓰는지 알아보자.
Redis?
Redis는 REmote DIctionary Server의 약자로, 고성능 인-메모리 데이터 저장소이다.(NoSQL)
하지만 단순히 저장을 위한 용도로 사용하지 않고 캐싱, 세션 관리, 실시간 데이터 분석, 메시지 브로커 등으로도 활용 가능하다.
이는 Salvatore Sanfilippo에 의해 기존 데이터베이스 시스템을 사용하여 실시간 웹 로그 분석기를 개발하던 중 일부 유형의 워크로드를 확장하는 데 문제가 발생하면서 개발되었다.
기본적으로 캐시 사용에 적합하도록 Low Latency의 빠른 데이터 읽고/쓰기를 위해 인-메모리를 사용하도록 디자인 되었다.
기업에서는 흔히 1차적으로 데이터 영속성, 무결성, 일관성 등을 위해 MySQL, PostgreSQL 등과 같은 데이터베이스를 사용하며, 2차적으로 성능 향상을 위하여 Redis의 캐싱 기능을 많이 활용한다.
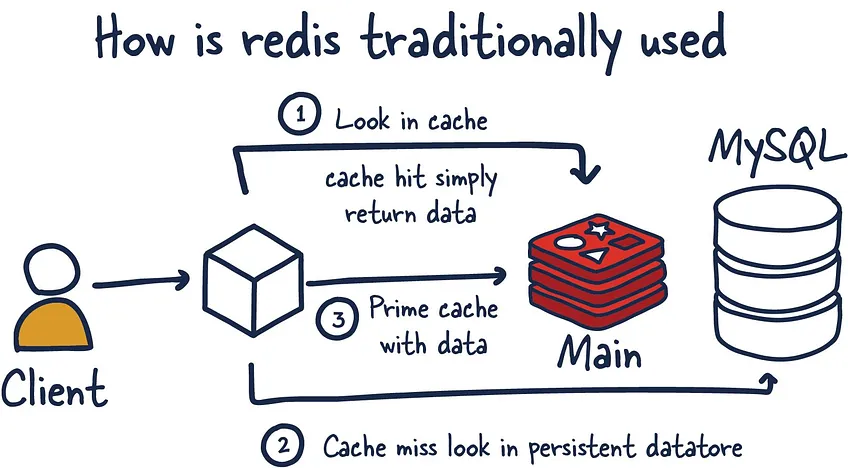 https://architecturenotes.co/p/redis
https://architecturenotes.co/p/redis
대표적으로 X(Twitter), Airbnb, Tinder, Yahoo, Adobe, Hulu, Amazon, OpenAI의 회사에서 Redis를 사용하고 있다.
특징
Low Latency
우리는 일반적으로 HDD, SDD와 같은 일반적인 디스크 기반 저장소를 사용한다.
하지만 이는 연산 처리를 위한 CPU와 직접적으로 연결되어 있지 않으며, 특히 HDD의 경우에는 물리적인 디스크에 데이터를 저장하고 이를 읽기 위해 디스크를 회전시키며 데이터를 찾는다.
결과적으로 CPU와 직접 연결된 RAM(Random Access Memory)에서 전기 신호를 통해 데이터를 읽고 쓰는 것 보다 속도가 느릴 수밖에 없다.
Redis는 RAM과 같은 메모리에 데이터를 저장하기에 디스크 기반 저장소보다 훨씬 빠른 성능을 제공한다.
Data types
기본적으로 Key-Value의 데이터 저장 구조를 넘어 다양한 데이터 저장 타입을 제공한다.
덕분에 사용하려는 환경에 맞게 원하는 데이터 타입을 채택하여 유연하고 높은 성능을 보장할 수 있다.
아래는 기본적으로 지원하는 데이터 타입이다.
- Strings : 가장 기본적인 데이터 타입으로 Key - Value의 구조를 가진다.
- Lists : 순서가 있는 목록으로 Queue, Stack 처럼 작동할 수 있다.
- Sets : 중복되지 않는 문자열의 집합이다.
- Sorted Sets : 우선 가중치를 가진 집합으로 가중치에 따라 정렬되기에 순위 기능에 유용하다.
- Hash Tables : O(1)의 시간복잡도를 가진 HashKey - Value 의 구조를 가진다.
- HyperLogLogs : 방대한 양의 데이터셋 항목 개수를 대략적으로 추정하는데 사용한다.
- Streams : 자동으로 시간 기반의 시퀀스를 기반으로 데이터를 저장하기에 실시간 로그나 이벤트 스트리밍에 적합하다.
- Geospatial Data : Geohash를 활용하여 지리적 좌표 값을 저장하기에 근접 검색과 같은 위치 기반 기능에 유용하다.
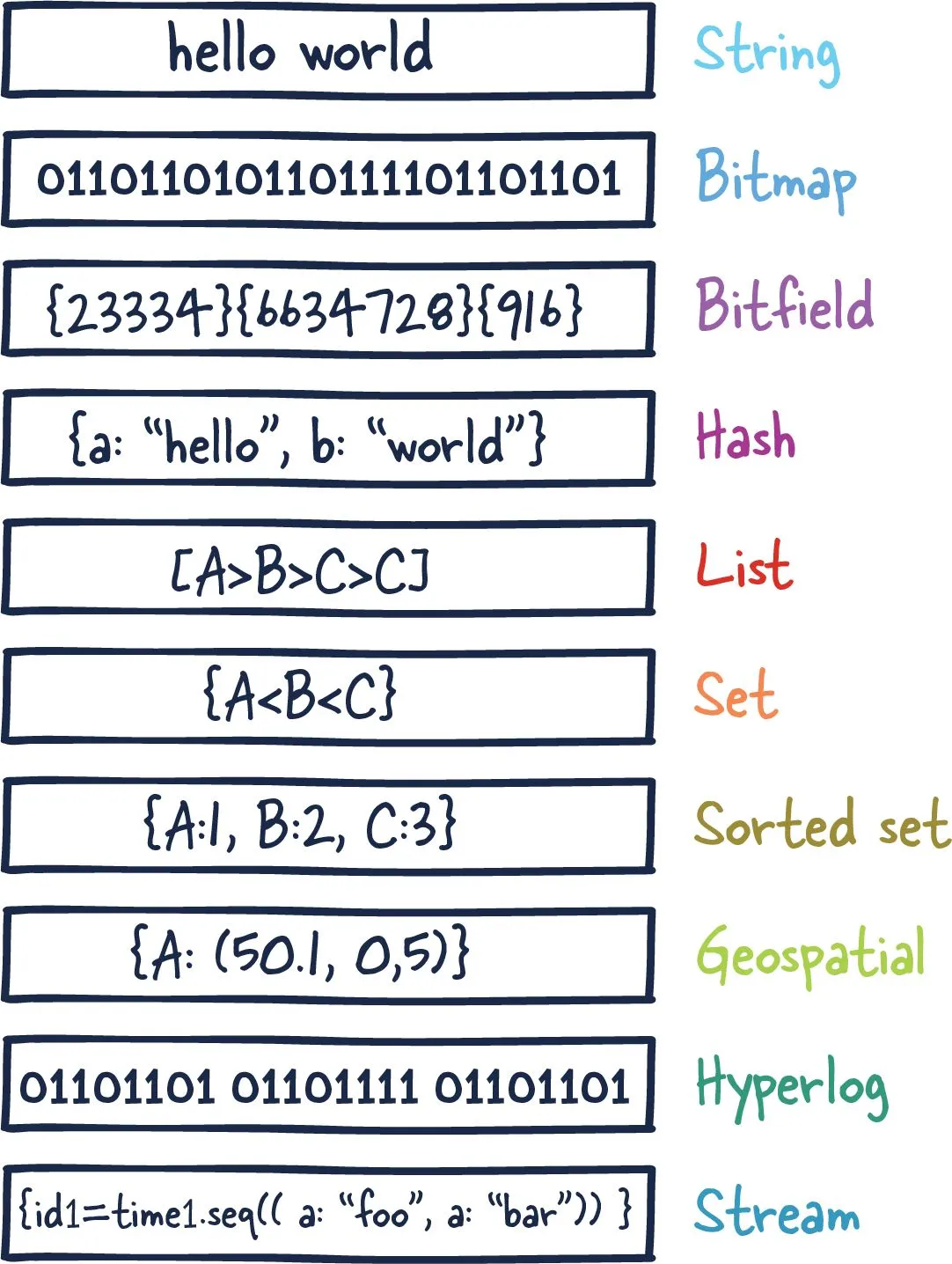 https://architecturenotes.co/p/redis
https://architecturenotes.co/p/redis
위와 같은 Strings 기반의 기본 데이터 타입 외에도 Redis Modules API를 통해 JSON, Search, Time series, Cuckoo filter, Count-min sketch, Top-K 등을 활용할 수 있다.
Persistence
메모리 저장 기반이기 때문에 데이터가 휘발될 수 있다.
하지만 데이터를 계속해서 보관하고 싶은 니즈에 맞춰 영속성(Persistence) 확보의 두 가지 방법을 제공한다.
RDB(Redis Database), Snapshotting
일정한 간격을 가지고 Redis RDB Dump File Format으로 메모리 데이터를 디스크에 저장한다.
간격동안에는 여러 개의 스냅샷을 생성하며 파일 복구 시에는 원하는 스냅샷을 기반으로 복구할 수 있다.
하지만 일정 주기를 가지는만큼 텀 간에 데이터 유실이 생길 수 있다.
Append-Only File(AOF)
데이터가 변경되는각 작업마다 로그 파일에 이를 기록한다.
변경 기록을 보관하고 있기에 최소한의 데이터 유실로 복구가 가능하다.
데이터의 크기가 무한하게 커지지 않도록 Journaling을 활용하고, Snapshotting에 비해 파일 크기가 큰 것이 단점이다.
데이터를 캐시로만 사용할 때는 데이터 유실이 크리티컬하지 않으니 RDB만을 사용해도 될 것이고, 최소한의 데이터 유실을 위한 복구가 우선이라면 AOF를 사용하면 될 것이다.
안정적이고 데이터 유실이 없어야하는 HA의 구조라면 RDB + AOF를 복합적으로 사용하여 데이터를 핸들링하는 것이 가능할 것이다.
Single Thread
실행한 명령어들은 Event Queue에 적재되고 이를 싱글 스레드로 하나씩 처리한다.(Event Loop)
싱글 스레드로 설계된 이유는
단순성
싱글 스레드 모델은 구현과 유지보수가 쉽다.
다중 스레드를 사용할 경우에는 Lock, Deadlock 즉, 병목 현상을 해결하기 위해 다양한 기법을 활용해야하지만 싱글 스레드는 복잡하게 병목 현상을 제어할 필요가 없어진다.
일관성
Event Queue에 적재된 명령어들은 순서를 가지고 처리가 되기 때문에 일관성을 유지하기 쉽다.
트랜잭션 처리와 같은 작업에서 유리해진다.
빠른 처리
메모리의 성능이 보장된 현대에 와서는 대부분의 작업은 단일 스레드에서도 빠르게 처리된다.
장점
이런 싱글 스레드 구조를 가진 Redis는
- Lock이 없기에 Lock로 인한 오버헤드를 제거하고 성능을 향상 시킬 수 있다.
- 코드가 단순해지고 버그가 적어지기에 유지보수와 디버깅에 용이하다.
- 네트워크 I/O와 메모리 접근이 주요 병목 지점이지만, 처리량이 빠른 메모리는 싱글 스레드에서도 높은 처리량을 유지할 수 있다.
단점
- 오버헤드가 큰 명령어를 처리하는 동안 다른 명령어를 처리하지 못한다.
- 높은 처리량이 필요한 경우에는 자원이 제한적일 수 있다.
응답 속도 저하의 문제를 극복하기 위해서는 여러 인스턴스를 실행하는 샤딩을 통해 부하를 분산시킬 수 있고, 여러 노드를 사용하는 클러스터 구성으로 확장성을 추구할 수 있다.
Pub/Sub Message
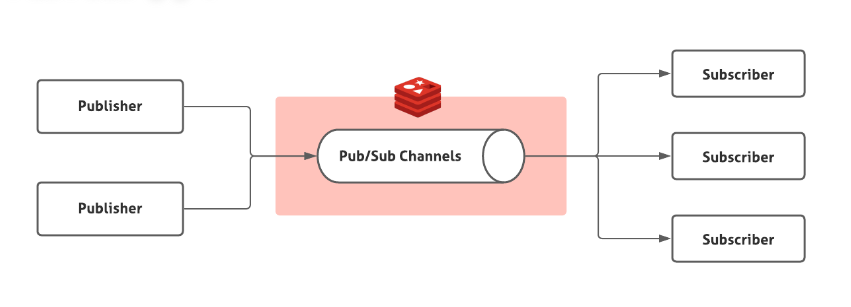 https://velog.io/@whdgnszz1/BE-Redis-PubSub%EC%9D%84-%EC%9D%B4%EC%9A%A9%ED%95%9C-%EC%9B%90%EA%B2%A9-%EB%A6%AC%EB%A1%9C%EB%93%9C-%EA%B8%B0%EB%8A%A5
https://velog.io/@whdgnszz1/BE-Redis-PubSub%EC%9D%84-%EC%9D%B4%EC%9A%A9%ED%95%9C-%EC%9B%90%EA%B2%A9-%EB%A6%AC%EB%A1%9C%EB%93%9C-%EA%B8%B0%EB%8A%A5
Publish / Subscribe의 실시간 메시지 브로커로 활용할 수 있다.
메시지를 제공하는 Publishser와 Publisher(Topic)를 구독하는 Subscriber로 Publisher가 본인을 구독한 Subscriber에게 메시지를 전달하고 이를 받는 구조를 가진다.
그리고 메시지를 전달하는 일종의 터널은 Channel로 불리우며, Redis가 Channel의 역할을 수행할 수 있다.
실시간으로 메시지를 전달하는데는 역시 Latency가 중요하겠으며, Redis는 Low Latency를 가졌기에 채팅 애플리케이션, 실시간 피드, 알림 시스템 등에 유용하게 사용할 수 있다.
하지만 Kafka, RabbitMQ 등과 같은 메시지 큐 시스템과 다르게 Subscriber가 없어도 메시지를 보관하지 않고 무조건 전달하기 때문에 데이터가 유실될 수 있다.
이를 방지하기 위해서 Redis Streams라던가 Kafka, RabbitMQ 등과 같은 메시지 큐 시스템을 함께 활용해야한다.
High Availability
부모 노드를 복제한 Replica 노드들을 통해 고가용성을 제공한다.
복제된 Replica는 다시 부모가 되어 다른 Replica를 복제할 수 있고, 이는 publish–subscribe의 패턴에 의하여 구현될 수 있다.
또한 Redis Cluster를 통해 수평적 확장을 지원하기에 큰 데이터셋과 높은 트래픽을 처리할 수 있다.
해당 내용은 하단에서 다룰 “아키텍처” 항목에서도 설명 될 것이다.
활용
위와 같은 특징으로
- 애플리케이션 성능 향상
- 세션 데이터 조회 및 관리
- 실시간 분석
- 메시지 브로커
- 리더보드 및 순위표
- 위치 기반 서비스 근접 검색
등의 영역에서 활용 가능할 수 있게된다.
Redis를 활용하는 기업 서비스들은
- Amazon : ElastiCache
- Google : Cloud Memorystore
- MS : Azure Cache
- Alibaba : ApsaraDB
등으로 소개하곤한다.
아키텍처
Redis가 어떤 것인지 어느정도 파악 됐다면 이제 어떤 구조로 Redis를 사용하는지 알아보자.
Single Redis Instance
Redis를 단독으로 활용하는 아키텍처다.
보통 작은 단위의 인스턴스 성능을 높이는데 사용한다.
Single Redis Instance에서는 메모리 및 서버 리소스가 충분히 주어지면 캐싱을 통한 성능 향상을 최소한의 설정만으로 구현할 수 있을 것이다.
하지만 Redis 인스턴스에 문제가 발생 했을 시에는 클라이언트의 요청을 Redis를 통해 읽을 수 없기에 성능 상승은 커녕 서비스 운영에 문제가 생길 수 있을 것이다.
또한 인스턴스 재시작 혹은 Failover 발생 시 데이터가 손실될 수 있기에 RDB Snapshotting, AOF를 설정하여 Persistence 설정을 해야할 것이다.
Redis HA, Replication
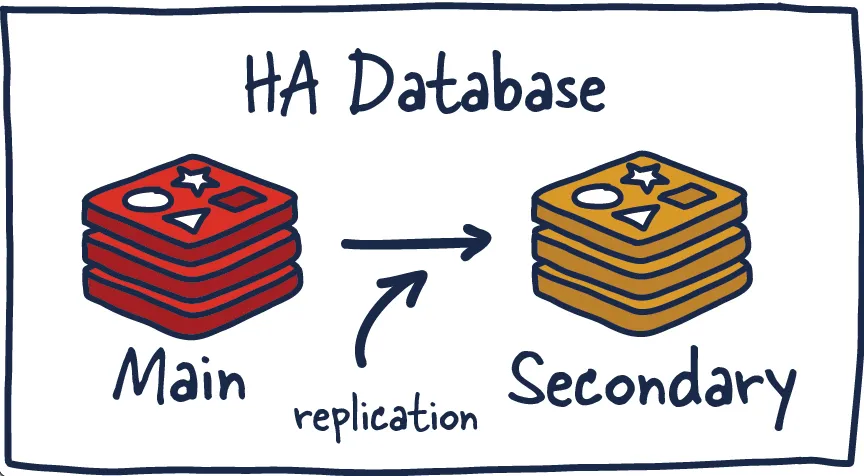 https://architecturenotes.co/p/redis
https://architecturenotes.co/p/redis
Replication을 이용하여 메인 인스턴스와 세컨더리 인스턴스의 싱크를 맞춰 유지해주는 일종의 Master-Slave 구조이다.
메인 인스턴스에 데이터가 쓰여질 때 해당 동작들을 Replication을 통해 세컨더리 인스턴스에 전달하여 같은 상태로 유지시킨다.
세컨더리 인스턴스는 하나 이상 구축해 놓고 읽기 요청을 분산하여 성능을 높이는 Scale Reads를 구현할 수 있고, 메인 인스턴스에 문제가 발생 했을 때 자동으로 백업 인스턴스로 전환하는 Failover도 활용할 수 있다.
위와 같은 Scale Reads와 Failover를 통해 기본적인 HA의 구조를 가져갈 수 있다.
Replication
참고로 Replication에 대해 더 설명하자면
메인 인스턴스가 replication ID와 offset을 가지고 있고, 해당 정보를 기반으로 Replication Process의 동기화 수행 시점을 파악한다.
방법에는 보통 2가지가 있다.
Partial Synchronization, 부분 동기화
복제본인 Replica가 메인 인스턴스와 오프셋 정도만 차이나는 비교적 적은 차이가 있는 경우에 사용한다.
즉, Replicaion ID는 같지만 offset이 다른경우에 사용할 수 있다.
Replica는 메인 인스턴스에게 자신이 현재 가지고 있는 offset 정보를 전달하고. 메인 인스턴스에서 현재 offset과 차이가 있을 때, 그 간격동안 수행되지 않은 명령어를 전달하고, Replica는 이 동작들을 수행한다.
차이나는 부분만 전달하고 실행하니, 빠르고 효율적이다.
Full Synchronization, 완전 동기화
Replica와 메인 인스턴스의 차이가 크게나는 경우나 Replica가 메인 인스턴스의 Replicaion ID와 offset을 알지 못하는 경우에 사용한다.
즉, 서로 상이한 Replicaion ID와 Offset 정보를 가지고 있을 때 사용할 수 있다.
Replica는 메인 인스턴스에 완전 동기화 요청을 보내고, 메인 인스턴스는 현재 데이터셋의 Snapshot(RDB)을 생성하고, 스냅샷 생성 이후에도 발생되는 동작을 버퍼링하여 Replica에게 전달한다.
부분 동기화보다 수행되는 동작이 많기 때문에 리소스가 많이 필요하다.
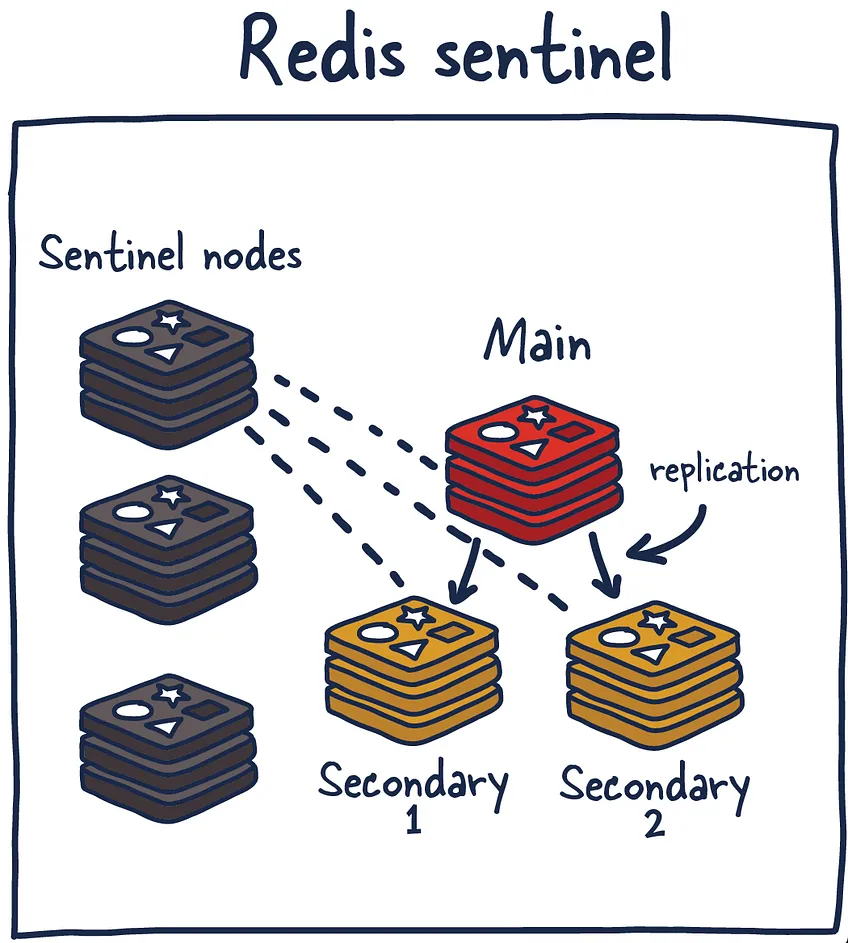
Redis Sentinel
 https://architecturenotes.co/p/redis
https://architecturenotes.co/p/redis
Redis Sentinel은 여러 개의 Sentinel 프로세스가 서로 협력하며 HA를 보장하는 분산 시스템이다.
Redis Sentinel 아키텍처는 Sentinel, Main(Master), Replica(Secondary)로 구성된다.
Sentinel
Sentinel은 보초, 망꾼, 감시 등으로 표현할 수 있다.
메인 인스턴스와 세컨더리 인스턴스의 상태를 확인하고 일종의 처리를 해주기 때문에 Sentinel라고 표현한 것 같다.
역할
- 메인 인스턴스와 세컨더리 인스턴스가 제대로 동작하는지 모니터링한다.
- 문제가 발생 했을 시 이벤트를 시스템 관리자에게 알려준다.
- 메인 인스턴스 사용 불가 상태라면 자동으로 Failover 수행.
- Zookepper, Consul 등과 같이 Service Discovery 역할로도 동작을 수행하여 현재 메인 인스턴스의 역할을 알아낼 수 있다.
Quorum
Sentinel은 여러개의 Sentinel Processes로 이루어질 수 있다.
Sentinel의 역할 중 하나인 “메인 인스턴스 사용 불가 상태라면 자동으로 Failover 수행.”를 위해서는 여러 개의 Sentinel들이 과반수 Failover를 수행할지 결정하게 된다.
여기서 동작이 수행될 때 필요한 최소 동의 수를 Quorum이라고한다.
구성
최소 3개의 Sentinel 노드를 실행하고, 2개의 quorum을 설정하는 것이 일반적이다.
Sentinelt의 인스턴스는 보통 애플리케이션 인스턴스와 동일한 서버에서 노드를 실행하여 네트워크 접근성 편차를 줄인다.
하지만 Quorum을 잃는 경우에 장애 조치가 제대로 되지 않을 수 있으며, 네트워크를 분리한다면 일부 데이터가 유실될 수 있고, 비동기적 Persistence로 인해 데이터 내구성이 보장되지 않을 수 있고, 새로운 메인 인스턴스를 발견하는 과정에서도 데이터가 유실 될 수 있으니 이를 보완할 수 있도록 추가적인 작업을 고려해야한다.
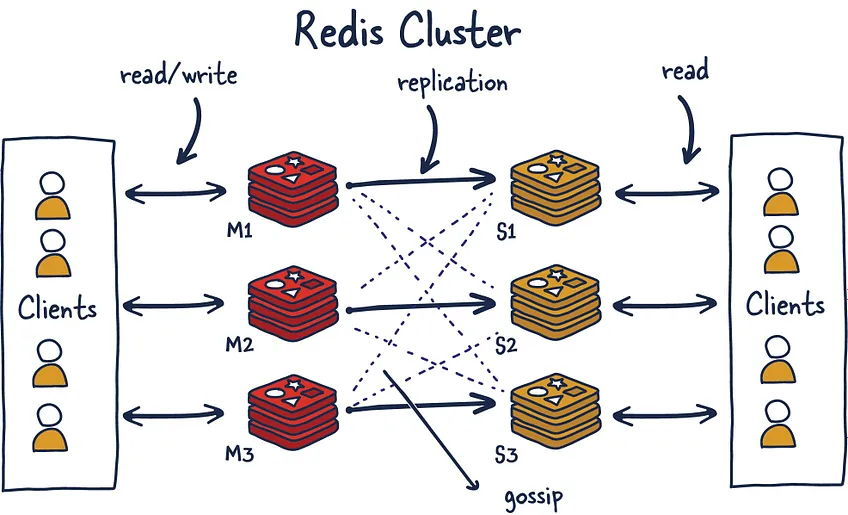
Redis Cluster
 https://architecturenotes.co/p/redis
https://architecturenotes.co/p/redis
일부 대규모 서비스를 운영하는 환경에서는 메모리 사용량이 부족할 수 도 있는 상황이 발생할 것이다.
이 때 Redis Cluster는 Redis의 수평적 확장을 지원한다.
Vertical and Horizontal Scaling
시스템의 확장을 위해서는 다음과 같은 옵션들이 있다.
- Scale Up
- Scale Out
이는 각각 Vertical Scaling(수직 확장), Horizontal Scaling(수평 확장)이라고 표현한다.
수직 확장은 더 좋은 하드웨어를 사용하여 서버의 성능을 올리는 것을 의미한다.
수평 확장은 서버의 개수를 늘려서 분산 작업에 활용하는 것을 의미한다.
수직 확장의 하드웨어 성능은 한계가 있기 때문에 보통은 수평 확장을 수행하는 편이다.
Sharding
Redis Cluster를 사용하면서 데이터를 여러개의 머신에 분산하여 저장하는 것을 Sharding이라고한다.
각각의 Cluster에 있는 Redis 인스턴스들은 전체 데이터의 Shard가 된다.
Algorithmic Sharding
Sharding을 수행했을 때 데이터를 조작한다면 어떤 Shard에 해당 데이터가 있는지 혹은 어떤 Shard에 데이터를 넣어야하는지 알아야한다.
이 떄 Redis Cluster는 Algorithmic Sharding라는 방식을 사용한다.
주어진 데이터의 키를 찾기 위해서 키를 해싱하고, 결과를 샤드 수로 나눈 나머지 값으로 데이터가 저장될 샤드의 위치가 결정된다.
이후 Deterministic hash function에 의해 같은 키가 입력되면 항상 동일한 값을 통해 샤드의 위치를 알려줄 것이다.
Resharding
데이터가 저장될 위치를 샤드 수를 나눈 나머지로 구하는 과정이 있었다.
하지만 샤드가 추가되거나 사라진다면 어떻게 해야할까?
이 때 실행되는 프로세스를 Resharding이라한다.
기존의 데이터의 위치를 다시 조정하는 과정을 수행하면서 복잡한 과정을 거쳐야하고, 데이터 정합성이 깨질 수 있는 과정에서 Redis Cluster는 이를 위해 Hashslot이라는 개념을 도입했다.
Hashslot
Resharding의 복잡하고 위험한 작업을 위해 고안된 Hashslot은 16,384개가 존재하며 각 Hashslot에 데이터를 맵핑한다.
클러스터 간에 데이터를 배분할 때, 새로운 샤드를 추가할 때 간단하게 Hashslot을 새로운 샤드로 이동시킴으로써 데이터 이동을 최소화한다.
예를 들어 기존에 두 개의 머신(M1, M2)이 있는 경우 Hashslot은
- M1 : 0 ~ 8191
- M2 : 8192 ~ 16383
을 포함한다.
이 때 키 ‘foo’의 키 값을 저장할 때
- 키 ‘foo’를 해싱하여 16,384로 나눈 나머지를 구한다(deterministic hash과 다르다.)
- 결과에 따라 해당 Hashslot이 M2에 매핑된다.
의 과정을 거칠 것이다.
이제 새로운 머신(M3)을 추가하게되면
- M1: 0 ~ 5460
- M2: 5461 ~ 10922
- M3: 10923 ~ 16383
와 같이 Hashslot이 배정될 것이고 샤드에 있던 일부 데이터들은 다른 샤드에 배정될 것이다.
이런 과정에서 데이터를 직접 다시 다른 샤드에 넣는 동작을 생략할 수 있게된다.
Gossiping
Redis Cluster는 전체 클러스터의 상태를 체크하는 Gossip Protocol을 통해 Gossiping을 수행한다.
위에서 보았던 이미지는 3개의 M 노드, 3개의 S노드를 가지고 있다.
모든 노드들은 어떤 샤드가 사용 가능한 상태이고, 요청을 처리할 수 있는지 확인하기 위해 끊임 없이 통신을 주고 받는다.
이 때 Quorum의 개념을 사용하여 M1노드가 응답하지 않는다고 다른 샤드끼리의 결론이 나면 M1의 Replica인 S1을 새로운 마스터로 승격 시켜 전체 시스템의 안정된 상태를 유지한다.(Failover)
이러한 과정을 통해 HA의 구조를 유지시키지만 노드 수를 적절하게 구성하지 않는다면 클러스터가 1:1, 2:2 등 짝수로 분리되어 동등한 Quorum을 발생시켜 결정할 수 없는 Split Brain이 발생될 수 있다.
클러스터 설정 시 일반적으로 홀수 개의 마스터 노드를 유지하고, 각 마스터는 2개의 replica를 주는 것을 권장한다.
Ref.
https://en.wikipedia.org/wiki/Redis