
[DB] Transaction, ACID, Isolation level
RDB의 목적에는 데이터를 효율적으로 다루고, 데이터간의 관계를 정의, 효율적인 검색, 일관성 유지 등의 목적을 가지고 있다.
여기서 일관성을 유지시키기 위한 Transaction, ACID, Isolation level 요소에 대해 알아보려고한다.
가장먼저 Transaction에 대해 알아보자.
Transaction
DB에 요청하는 일련의 작업을 하나의 작업 단위로 처리하는 것을 의미한다. 데이터의 일관성, 무결성, 신뢰성을 보장하기 위한 역할이다.
위와 같은 일관성, 무결성, 신뢰성이 보장시켜 주는 트랜잭션 단위로 요청을 처리하지 않게 된다면 아래와 같은 상황이 발생할 수 있다.
보통은 예시를 들 때 돈을 송금하기 위해 계좌에서 돈을 뺐는데 이 과정에서 네트워크 문제가 발생해서 돈은 빠져나갔는데 상대방의 계좌에 입금되지 않은 상황을 예시로 많이 든다.
하지만 다른 은행 업무를 예시로 들자면(적절할지 확신이 안 든다….),
A라는 사용자가 50,000원의 잔액을 가지고 있을 때 이를 자동으로 이체하여 출금 하기 원하는 B 업체와, C 업체가 있다.
각각 50,000원을 출금하기 원하기에 잔액은 100,000원이 있어야 한다. (마이너스 통장 제외 하하)
먼저 B가 A의 계좌를 조회해서 50,000원이 있다는 걸 확인하고 출금을 지시한다. 하지만 이를 ms 단위마저 똑같은 시점에 B 또한 요청하게 되고 B에서 아직 출금이 끝나지 않아 50,000원의 잔액이 있다고 판단하고 똑같이 50,000원을 출금을 지시한다.
B가 출금을 지시하고 잔액을 빼기도 전에 C도 같은 동작을 수행하고 있으니 각각 50,000원을 본인 계좌에 받을 수 있는 상황이 벌어진다.
100,000원이 없는데 100,000원을 쓸 수 있게 되는 상황이 발생하는 것이다.
위와 같은 상황을 회피하기 위해 트랜잭션을 활용해야 한다.
그럼 어떤 특성 때문에 일관성, 무결성, 신뢰성을 보장할 수 있게 된 걸까?
ACID
트랜잭션은 ACID를 준수한다.
하나씩 알아보자.
Atomicity, 원자성
트랜잭션의 모든 작업이 성공적으로 반영되거나, 실패하면 이전 상태로 Rollback 해야 한다.
Consistency, 일관성
트랜잭션으로 저장하려는 데이터는 테이블에서 정의한 형식(int,char,date…)의 데이터 타입과 정확히 일치돼야 한다.
혹은 트랜잭션이 완료되어도 기존에 설정하였던 제약 조건이 변경되면 안 된다.
Isolation, 고립성
A, B의 트랜잭션이 동시에 실행되고 있을 때, A의 중간 작업을 B가 볼 수 없거나, 일부만 보이게 되고, 서로 간섭하지 않아야 한다.
Durability, 영구성
Atomicity로 결과가 성공적으로 완료되었을 때의 마지막 상태를 영구적으로 보존해야 한다.
이는 시스템 장애가 발생하더라도 결괏값을 보존해야 한다는 의미다.
Transaction의 상태
트랜잭션이 무엇이고, 어떤 걸 보장해야 하는지 알아보았다.
그렇다면 트랜잭션은 어떤 동작 상태를 가지고 있을까?
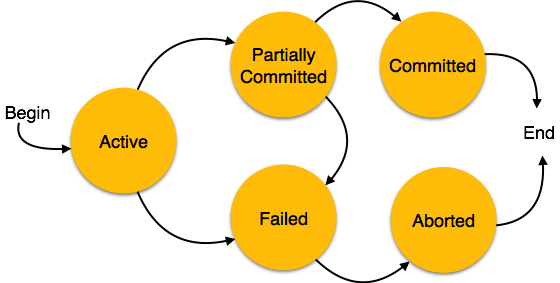
https://www.tutorialspoint.com/dbms/dbms_transaction.htm
Active, 활성
트랜잭션이 실행되었으며, 아직 완료되지 않은 상태.
모든 트랜잭션이 공통으로 가지고 있는 상태다.
Partially Committed, 부분 완료
트랜잭션의 마지막 명령어가 수행됐지만, 최종 반영되지 않은 상태다.
Failed, 실패
트랜잭션 실행 중 하나라도 오류가 발생하여 더 이상 진행되지 않는 상태.
Failed 상태 선정은 데이터베이스 복구 시스템에서 수행한다.
Aborted, 중단
트랜잭션 Failed가 되면 트랜잭션의 수행 전 원래의 상태로 복구시키는 상태.
이때
- 트랜잭션 재시작.
- 트랜잭션 Kill.
의 복구 모듈을 선정할 수 있다.
Committed, 완료
트랜잭션의 동작이 모두 성공적으로 완료되었을 때 데이터베이스에 영구적으로 저장된 상태.
Transaction의 제어 명령어.
DB들은 보통 기본적으로 auto commit으로 설정이 되어있는데, 이는 직접 COMMIT과 같은 명령어를 입력하지 않아도 시작에서부터 COMMIT까지의 동작을 자동으로 실행해 준다.
트랜잭션을 제어하기 위해서 사용하는 명령어들은 아래와 같다.
BEGIN / START TRANSACTION
트랜잭션의 시작을 알린다.
BEGIN;
COMMIT
트랜잭션을 완료하고, 모든 변경 사항을 DB에 영구적으로 반영한다.
COMMIT;
ROLLBACK
트랜잭션을 중단하고, 모든 변경 사항을 트랜잭션 시작 전 상태로 복구시킨다.
ROLLBACK;
SAVEPOINT
트랜잭션 내에서 특정 지점을 저장하여, 필요시 해당 지점으로 롤백하는 시점을 저장한다.
SAVEPOINT savepoint_name;
RELEASE SAVEPOINT
지정한 SAVEPOINT를 제거한다.
RELEASE SAVEPOINT savepoint_name;
ROLLBACK TO SAVEPOINT
트랜잭션을 지정한 SAVAPOINT로 롤백한다.
ROLLBACK TO SAVEPOINT savepoint_name;
우리는 단순히 DML 문을 작성하여 쿼리를 실행했지만 내부에서는 위와 같은 제어 명령어들이 포함된 코드를 실행한다.
BEGIN;
INSERT INTO table1 VALUES (3);
SAVEPOINT my_savepoint;
INSERT INTO table1 VALUES (4);
RELEASE SAVEPOINT my_savepoint;
COMMIT;
와 같은 명령어와 같이.
Transaction Serializability, 직렬화
멀티프로그래밍 환경에서 여러 트랜잭션이 실행되는 경우 한 트랜잭션의 명령어가 다른 트랜잭션과 상호 동작할 수 있는 상황이 발생한다.
트랜잭션은 스케줄이라는 실행 순서를 가진다.
Serial, 스케줄
시간에 따른 실행 순서를 의미한다.
스케줄에는 여러 개의 명령과 작업으로 구성된 여러 트랜잭션이 함께 포함될 수 있다.
Serial Schedule, 연속 스케줄
트랜잭션의 실행이 연속적으로 이루어지는 것을 의미한다.
첫 번째 트랜잭션이 사이클을 완료하면 다음 트랜잭션이 실행되는 일종의 Chaining 방식으로 실행된다.
여기서 연속 스케줄은 다중 트랜잭션 환경에서 실행의 기준이 된다.
하나의 트랜잭션은 명령의 실행 순서를 바꿀 수 없지만, 두 개의 트랜잭션은 명령을 무작위 방식으로 실행할 수 있게 된다.
두 개의 트랜잭션이 각각 독립적이고 서로 다른 영역에서 작업하는 경우에는 영향을 주지 않겠지만, 트랜잭션이 동일한 영역에서 작업하는 경우에는 영향을 줄 가능성이 크기에 보장할 수 있는 데이터 유지가 불가능해진다.
이러한 문제를 해결하기 위해 트랜잭션들을 각각 직렬화할 수 있거나(serializable), 트랜잭션 간에 동등한 관계가 있는 경우에 트랜잭션의 동작을 병렬로 실행시킬 수 있다.
Equivalence Schedules, 동등 스케줄
동등 스케줄은 아래와 같은 타입들을 사용할 수 있다.
Result Equivalence, 결과 동등
두 개의 스케줄이 실행 후 같은 결과를 만들어 낸다면 이를 결과 동등이라고 표현한다. 하지만 어떤 값에 대해서는 동일한 결과가 나올 수도, 다른 값 집합에 대해서 다른 결과가 나올 수 있으니, 결과 동등은 일반적으로 중요한 요소로 여기지 않는다.
View Equivalence
두 스케줄의 트랜잭션이 유사한 방식으로 유사한 동작을 수행할 때 이를 View Equivalence라고 한다.
예시로는
- T가 S1에서 초기 데이터를 읽으면 S2에서도 초기 데이터를 읽는다.
- T가 S1에서 J가 쓴 값을 읽으면 S2에서 J가 쓴 값도 읽는다.
- T가 S1의 데이터 값에 대한 최종 COMMIT을 마치면 S2의 데이터 값 또한 COMMIT을 수행한다.
Conflict Equivalence, 충돌 동등
아래와 같은 성질을 가지고 있다면 충돌을 발생시킨다.
- 서로 다른 트랜잭션.
- 동시에 같은 데이터에 접근.
- 하나의 트랜잭션에서 쓰기 작업.
서로 상충하는 작업과 여러 트랜잭션이 있는 두 개의 스케줄은 다음과 같은 경우에만 충돌에 해당한다고 한다.
- 두 스케줄 모두 동일한 트랜잭션 세트를 포함.
- 두 스케줄 모두 충돌되는 작업의 세트가 유지.
Transaction Isolation Level, 트랜잭션 격리 수준
동시에 여러 트랜잭션이 수행될 때, 트랜잭션의 고립성을 보장하기 위해 격리 수준을 설정할 수 있으며, 수준에 따라 일관성과 동시성 제어에 차이가 생긴다.
크게 4가지의 격리 수준이 있으며, 내려갈수록 고립 수준이 높아지며, 동시에 제약 사항이 많아지기에 성능이 떨어진다.
Read Uncommitted
다른 트랜잭션에서 아직 COMMIT 되지 않은 데이터를 읽을 수 있는 격리 수준이다.
데이터 무결성이 낮으며, Dirty Read 문제가 발생할 수 있다.
여기서 Dirty Read 문제라는 것은
- A 트랜잭션에서 데이터를 수정하고 하직 COMMIT 않음
- COMMIT 되지 않은 값을 B 트랜잭션이 읽음(Dirty Read)
- A 트랜잭션에 문제가 발생하여 ROLLBACK 함.
- B는 읽은 값이 ROLLBACK 되어도 그대로 값을 사용함.
데이터 정합성의 문제가 생기기 쉽기 때문에 격리 수준이라고 보기 어렵다.
Read Committed
다른 트랜잭션에서 Commit 된 데이터만 읽을 수 있는 격리 수준이다.
Oracle에서 기본적으로 사용하는 격리 수준으로, 평균적으로 많이 채용하는 격리 수준이다.
Dirty Read의 문제는 해결될 수 있지만 Non-repeatable Read의 문제가 발생할 수 있다.
일단 Repeatable Read라는 건 동일한 트랜잭션 내에서 같은 데이터를 두 번 SELECT 했을 때, 첫 번째와 두 번째의 결괏값이 다르면 안 된다는 특징이다.
하지만 SELECT 사이에 다른 트랜잭션이 값을 변경하고, COMMIT 하였다면 이후 SELECT에서 다른 결괏값이 나오게 된다.
- A 트랜잭션은 2번의 SELECT 중에 첫 번째 SELECT로 데이터를 읽어서 10이라는 결괏값이 나옴.
- B가 해당 필드를 12로 바꿈.
- A 트랜잭션에서 두 번째 SELECT를 할 때 10이 나와야 하지만 12가 나옴.
이것이 Non-repeatable Read의 문제다.
평균적으로 많이 사용하지만 짧은 시간 내에 많은 데이터가 수정되고 읽힐 때 결괏값을 정확히 예측하고 사용해야 한다.
Repeatable Read
위에서 얘기한 Non-repeatable Read를 해결하는 격리 수준이다.
트랜잭션이 시작되기 “전에 커밋 된 내용”에 대해서만 조회할 수 있다.
다시 말해 트랜잭션이 시작된 시점에 존재했던 데이터만 읽어온다는 것이다.
MySQL에서 기본으로 사용하고 있는 격리 수준이다.
트랜잭션이 순서대로 실행될 때 각 실행 순서를 가지고 있다.
본인의 트랜잭션 번호보다 낮은 트랜잭션 번호에서 COMMIT된 데이터만 읽게 되어 Read Committed의 Non-repeatable Read의 문제를 해결할 수 있다.
- 1번 트랜잭션이 10을 COMMIT
- 2번 트랜잭션은 2번의 SELECT 중에 첫 번째 SELECT로 데이터를 읽어서 10이라는 결괏값이 나옴.
- 3번 트랜잭션이 10에서 13으로 값을 변경하여 COMMIT
- 2번은 2번째 SELECT 시 자신의 트랜잭션 번호보다 낮은 1번 트랜잭션이 COMMIT 한 값 10의 결괏값을 읽어옴.
하지만 이 격리 수준도 Phantom Read 문제가 발생할 수 있다.
트랜잭션 내에서 동일한 쿼리를 두 번 실행했을 때, 처음 실행 시에는 존재하지 않았던 레코드가 두 번째에서는 나타나는 형상을 의미한다.
- A 트랜잭션에서 조건에 만족하는 값을 읽어서 2개의 레코드를 읽음.
- B 트랜잭션에서 새로운 레코드를 삽입함.
- A 트랜잭션에서 다시 조건에 만족하는 값을 읽었는데 2개가 아닌 3개의 레코드가 읽힘.
Serializable
가장 높은 격리 수준으로, SELECT 작업에서조차 공유 잠금이 설정되어 잠금 설정되는 동안 다른 트랜잭션은 해당 레코드를 변경하지 못한다.
모든 격리 문제를 해결할 수 있지만 성능이 보장되진 않는다.
DB별 Isolation Level
마지막으로 DB별로 사용하는 격리 수준을 보고 마무리하겠다.
- READ COMMITTED: PostgreSQL, Oracle, SQL Server, Db2
- REPEATABLE READ: MySQL, MariaDB
- SERIALIZABLE: SQLite
Ref.
https://chrisjune-13837.medium.com/db-transaction-%EA%B3%BC-acid%EB%9E%80-45a785403f9e