
[JPA] 기본적인 JPA의 개념과 구현
ORM 즉, Object Relational Mapping이라는 개념이 있다.
흔히 이야기하는 객체와 DB의 테이블 간의 관계를 설정하는 것을 의미한다.
ORM 자체를 다룰 것은 아니고, Java군에서 이런 ORM 개념을 사용할 수 있는 JPA에 대해 알아 볼 것이다.
JPA
Java Persistence API의 약자다.
Persistance와 API의 단어가 눈에 띄는데 Persistence는 영속성이라 표현하는데 쉽게 풀어 설명하자면 저장된 데이터를 영구적으로 지속시킨다 라는 의미를 가진다.
RDB ACID 성질 중 Durability(영구성)에 대응 되는 개념이라 보면된다.
또한 API라고 표현이 되어있는데 이는 JPA가 바로 사용할 수 있는 구현체가 아닌 인터페이스라는 의미를 가진다.
그렇다 JPA는 인터페이스이자, Java군에서 ORM 기능을 사용하기 위한 기준이다.
JPA의 규칙에 맞춰 사용자가 쉽게 ORM을 이용할 수 있는 구현체는 대표적으로 Hibernate가 있다.
이런 JPA를 통해서 데이터베이스 데이터를 저장, 조회, 수정, 삭제하는 DML 역할을 수행할 수 있고, 개발자는 쿼리문을 직접 작성하지 않아도 되기에 비지니스 로직에 집중할 수 있게된다.
인터페이스인 Spring Data API와 함께 구현체인 Hibernate를 사용할 것이다.
Hibernate는 유연하고, 사용자 친화적이며, 성능이 우수하다는 장점이 있지만 제대로 활용하기 위해서는 학습이 필요하다.
Spring Data API는 Spirng 기반의 프로젝트에 별 다른 설정 없이 간편하게 사용할 수 있다는 장점이 있지만 기존 JPA를 한 단계 더 추상화 시킨 연유로 좀 더 무겁다고 볼 수 있다.
간단하게 JPA를 구현해보면서 개념에 대해 이해해보자.
Dependencies
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
developmentOnly 'org.springframework.boot:spring-boot-devtools'
runtimeOnly 'com.h2database:h2'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
testCompileOnly 'org.projectlombok:lombok'
testAnnotationProcessor 'org.projectlombok:lombok'
}
JPA, Lombok, H2, web, test를 사용할 것이다.
application.properties
spring.application.name=jpaDemo
# 데이타 소스 정의
#계정
spring.datasource.username=sa
spring.datasource.password=
# H2 Database 사용 선언.
spring.datasource.driver-class-name=org.h2.Driver
# H2 웹 콘솔 허용
spring.h2.console.enabled=true
# JPA 설정
spring.jpa.database=h2
# JPA 실행 시 쿼리문 로그 출력
spring.jpa.show-sql=true
# 쿼리문 로그 출력 시 포멧 설정.
spring.jpa.properties.hibernate.format_sql=true
Entity 정의
테이블 맵핑을 위한 데이터 객체로 활용되는 Entity, 일종의 DTO, VO와 비슷한 개념이라 생각하면 된다.
고객 정보를 담는 users Table이 있고, 속성에는 ID, name 가 있을 때 우리는
@Entity
@Data
public class Users {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long userId;
private String userName;
}
와 같은 Data Object 즉, Entity를 정의 해줘야한다.
참고로 오브젝트명을 User로 지정하게되면 서비스 실행 시 org.springframework.boot.autoconfigure.security.SecurityProperties.User 의 User로 인식하여 추가 설정이 필요할 수 있으니 Users로 사용하자
@Entity의 어노테이션은
- 해당 클래스가 DB의 테이블과 맵핑된다.
- JPA에 의해 관리되는 엔티티로 간주하여 생명주기를 관리한다.
- 쿼리 메서드를 작성할 수 있게 해준다.
@Table과 같이 매핑되는 테이블을 설정하지 않는다면 기본적으로 클래스 이름과 동일한 테이블을 매핑하게된다.
의 설정을 해준다.
추가로 엔티티가 되는 클래스는 ID를 가지고 있어야한다.
Repository Interfaces 정의
실직적으로 DB에 접근하여 데이터를 조작하는 DAO의 역할을 수행할 것이다. 먼저 도메인 클래스를 작성해야한다.
interface 로 작성할 것이며 Repository<T, ID>를 extends 하고, 도메인 클래스에는 ID가 정의되어야한다.
extends 하는 인터페이스에는 CrudRepository, PagingAndSortingRepository, ReactiveSortingRepository 등 여러가지가 있으며 특정한 기능을 사용하고 싶으면 성질에 맞는 Repository를 extends 하자.
우리는 간단하게 아래와 같이 사용하자.
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
}
너무 휑하지 않은가?
이럼에도 CRUD의 동작을 수행할 수 있다.
JpaRepository<T, ID>는
public interface JpaRepository<T, ID> extends ListCrudRepository<T, ID>, ListPagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
로 정의 되어있다.
기본적으로 JPA를 사용하기 위해서는 Repository<T, ID> 인터페이스를 이용하게되는데 이는 모든 Reporitory의 베이스가 된다.
save, saveAll, delete 등이 정의되어있는 CrudRepository<T, ID>도 Repository<T, ID>를extends 하고,
Pageable 인터페이스를 이용해 Pagination을 활용할 수 있는 PagingAndSortingRepository<T, ID> 도 Repository<T, ID>를extends 한다.
JpaRepository<T, ID>는 위에 CrudRepository<T, ID>,PagingAndSortingRepository<T, ID>는 물론 다른 인터페이스를 모두 extends해놓은 interface이다.
JpaRepository의 interface 구조를 이미지로 표현하자면
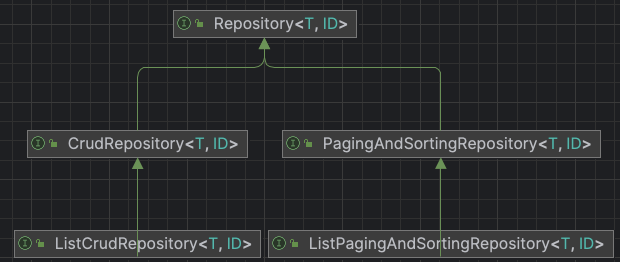
와 같다.
JpaRepository 를 extends하게되면 위의 interface를 모두 extends하는 이유로 UserRepository는 내부에 있는 메서드들을 모두 정의할 수 있게된다.
기본으로 제공하지 않는 기능을 정의한다면 Repository Interfaces에 직접 메서드를 정의할 수 있다.
@Repository
public interface UsersRepository extends JpaRepository<Users, Long> {
List<Users> findFirst2ByUserNameLikeOrderByUserIdDesc(String userName);
}
와 같이 말이다.
findFirst2ByUserNameLikeOrderByUserIdDesc의 의미는 userName을 기준으로 값을 찾은 뒤 userId를 기준으로 내림차순 정렬을하고 여기서 먼저 나오는 결과 2개만 찾는 메서드가 된다.
이를 Query Method라고 부르는데, 단어 조합으로 동작을 정의하는 것을 의미한다.
자세한 사항은 Query Method 포스트에서 알아보겠지만 현재 상황에서 LIKE 조회는 % 를 직접 Parameter에 포함시켜야한다.
이유는 Query Method의 정의어로 StaringWith, EndingWith, Like, Contains가 가지는 특징이 다르기 때문이다.
“재훈맨” 이라는 Parameter가 부여되면
StartingWith: “재훈맨%”EndingWith: “%재훈맨”Contains: “%재훈맨%”
의 형식으로 자동 변환되는데반해 Like는 넘겨주는 Parameter에 직접 %를 포함시켜 줘야한다.
Test
H2 in-memory 영역에 users table을 생성하여 Users의 객체를 넣고, 이를 조회하는 테스트를 진행하겠다.
@DataJpaTest
@Slf4j
class JpaTest {
@Autowired
UsersRepository usersRepository;
// 메서드 실행 전에 실행되어야 할 작업을 정의한다.
@BeforeEach
void insertTestData() {
// 사용자 정의 객체 Users를 인스턴스화, set 하여 save한다.
Users user = new Users();
user.setUserName("jaehoonman");
usersRepository.save(user);
user = new Users();
user.setUserName("jaehoonwoman");
usersRepository.save(user);
user = new Users();
user.setUserName("jaehoonboy");
usersRepository.save(user);
user = new Users();
user.setUserName("jaehoongirl");
usersRepository.save(user);
}
// 모든 저장 데이터를 호출하는 테스트
@Test
void findAllTest() {
// JpaRepository extends 하면서 기본적으로 정의된 findAll() 메서드를 사용한다.
List<Users> usersList = usersRepository.findAll();
log.info("#### findALl ####");
for(Users u : usersList){
log.info( u.getUserId() + ", " +u.getUserName());
}
log.info("#############");
}
// parameter로 주어진 값과 LIKE 조회하여 일치하는 데이터 2개만 가져오기.
@Test
void findFirst2ByUserNameTest() {
// 직접 '%'를 부여하여 StartingWith 처럼 동작하게.
List<Users> usersList = usersRepository.findFirst2ByUserNameLikeOrderByUserIdDesc("jaehoon%");
log.info("#### findFirst2ByUserNameLikeOrderByUserIdDesc ####");
for(Users u : usersList){
log.info(u.getUserId() + ", " +u.getUserName());
}
log.info("#############");
}
}
참고로 @DataJpaTest + @RequiredArgsConstructor 는 기본적으로 JUnit 5의 테스트 환경에서 생성자 주입을 하지 않기 때문에 @Autowired 를 이용하여 Repository를 주입 받자.
findAllTest()의 테스트를 실행해보면,
jpaDemo] [ Test worker] org.jaehoonman.jpademo.JpaTest : Starting JpaTest using Java 21.0.3 with PID
[jpaDemo] [ Test worker] .s.d.r.c.RepositoryConfigurationDelegate : Finished Spring Data repository scanning in 20 ms. Found 1 JPA repository interface.
[jpaDemo] [ Test worker] o.s.j.d.e.EmbeddedDatabaseFactory : Starting embedded database: url='jdbc:h2:mem:41452aeb-068f-448a-afe4-b98226324a71;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=false', username='sa'
[jpaDemo] [ Test worker] org.hibernate.Version : HHH000412: Hibernate ORM core version 6.4.4.Final
등의 테스트 환경 Initialize 가 일어난다.
Hibernate:
drop table if exists users cascade
Hibernate:
create table users (
user_id bigint generated by default as identity,
user_name varchar(255),
primary key (user_id)
)
JPA의 구현체인 Hibernate는 기본적으로 @Entity로 지정된 객체의 테이블을 create-drop하기에 위와 같은 DDL 쿼리가 먼저 실행된다.
테스트 환경은 괜찮지만 운영 환경에서 위와 같은 설정이 적용된다면 대참사가 일어날 수 있다.
jpa.hibernate.ddl-auto의 옵션은
- create: 기존 테이블이 없으면 생성하고, 있으면 그대로 유지.
- alter: 기존 테이블 구조를 엔티티 클래스와 일치하도록 변경.
- create-drop: 기존 테이블을 모두 삭제하고 엔티티 클래스를 기반으로 새 테이블을 생성.
- validate: 엔티티 클래스와 데이터베이스 스키마가 일치하는지 확인하고, 일치하지 않으면 예외를 발생.
-
none: Hibernate가 스키마를 변경하지 않음. 와 같으니 상황에 맞는 옵션을 꼭 지정하자.
- 개발 환경:
create-drop또는alter를 사용하여 테이블을 빠르게 생성하거나 변경. - 테스트 환경:
create-drop또는validate를 사용하여 테스트 전에 테이블을 초기화하고 테스트 후에 삭제. - 운영 환경:
none또는validate를 사용하여 기존 테이블 구조를 유지하고, 데이터 손실을 방지.
이후 @BeforeEach로 지정해둔 insertTestData()의 동작이 실행된다.
Hibernate:
insert
into
users
(user_name, user_id)
values
(?, default)
Hibernate:
insert
into
users
(user_name, user_id)
values
(?, default)
Hibernate:
insert
into
users
(user_name, user_id)
values
(?, default)
Hibernate:
insert
into
users
(user_name, user_id)
values
(?, default)
마지막으로 실행한 findAllTest()가 수행되며 findAll한 결과를 도출해낸다.
Hibernate:
select
u1_0.user_id,
u1_0.user_name
from
users u1_0
...
#### findALl ####
1, jaehoonman
2, jaehoonwoman
3, jaehoonboy
4, jaehoongirl
#############
transaction이 실행되고 난 뒤에는 drop을 실행하고 Pool을 close한다.
[jpaDemo] [ionShutdownHook] j.LocalContainerEntityManagerFactoryBean : Closing JPA EntityManagerFactory for persistence unit 'default'
Hibernate:
drop table if exists users cascade
findFirst2ByUserNameTest()을 실행하게되면 초기화 과정을 마치고
Hibernate:
select
u1_0.user_id,
u1_0.user_name
from
users u1_0
where
u1_0.user_name like ? escape '\'
order by
u1_0.user_id desc
fetch
first ? rows only
...
#### findFirst2ByUserNameLikeOrderByUserIdDesc ####
4, jaehoongirl
3, jaehoonboy
#############
가 수행된다.
DB와 Interaction이 정상적으로 되는 것을 확인 했으니 Service Layer와 Controller를 작성해보자.
Service Layer 작성
Controller에서 오는 Request를 Repository interaction 할 동작을 지정해준다.
현재는 조회와 삽입 동작만 정의하였다.
@Service
@RequiredArgsConstructor
public class UsersService {
/**
* Controller를 통해 들어오 요청을 DB와 Interaction하기 위한 서비스 레이어.
*/
// @RequiredArgsConstructor 를 사용하여 Dependencies 생성자 주입.
private final UsersRepository userRepository;
// Users 정보를 조회한다.
public List<Users> getUsers(String userName){
// userName 파라미터를 제공 받지 않았다면 findAll로 모든 정보를 가져온다.
if(userName.isBlank()){
return userRepository.findAll();
}
// userName을 받아왔다면, Like 조회를 통해 상위 2개를 return
else {
// JPA의 LIKE는 직접 '%' 를 포함시켜야한다.(인코딩 핸들링 대신 직접 넣어주는걸로...)
return userRepository.findFirst2ByUserNameLikeOrderByUserIdDesc(userName + "%");
}
}
/**
* 고객 정보 DB 저장.
* @param user
* @return
*/
public String createUser(Users user){
userRepository.save(user);
return "등록 완료";
}
}
위에서도 설명했듯이 JPA의 LIKE 조회는 직접 %를 부여하여 StaringWith, EndingWith, Contains 를 지정해야한다.
현재는 StaringWith를 수행하는데 Parameter로 받아온 값에 직접 %를 COW 하였는데 URL을 통해 %나 한글과 같은 특수 문자를 포함시키면 기본적으로 HTTP 통신은 이를 URL Encoding 형식으로 변환한다.
Controller에서 GET 방식으로 @RequestParam으로 userName Parameter를 가져올 때 Decoding 한다던가 추가 설정이 필요할 수 있으므로 이를 회피하기위해 간단히 값을 변경했다.
Controller
@RestController
@RequiredArgsConstructor
@RequestMapping("/user") // REST API 요청 시 prefix를 설정.
public class UsersController {
private final UsersService usersService;
/**
* 고객 정보를 조회한다.
* userName으로 Param을 받았다면 LIKE 조회를, 아닐 시 전체 조회를 수행한다.
* userName과 LIKE 조회하여 해당되는 고객 정보 GET
* 클래스 단위로 @RequestMapping를 설정하여 GET "/user" 로 요청 시 맵핑된다.
* @param userName
* @return
* @RestController 를 설정했기에 자동으로 결과 값을 JSON으로 return해준다.
*/
@GetMapping
public List<Users> getUsers(@RequestParam(required = false, defaultValue = "") String userName){
return usersService.getUsers(userName);
}
/**
* POST 요청 시 받아오는 Body 값을 Users 데이터 객체로 변환하여 저장한다.
* @param user
* @return
*/
@PostMapping
public String createUser(@RequestBody Users user){
return usersService.createUser(user);
}
}
의존성으로 주입한 Spring web의존성을 통해 @RestController를 설정하여 @ResponseBody 설정 없이 Response를 JSON으로 Response할 수 있도록 설정하자.
클래스 단위에서 제공한 @RequestMapping("/user")로 인하여 “/user”의 경로로 GET/POST 요청을 핸들링할 수 있다.
GET 요청 시에는 @RequestParam의 옵션으로 인해 userName의 Parameter를 제공 받지 않을 시 기본값으로 ““를 설정하였다.
Service에서 if(userName.isBlank()){ 을 위한 처리라 할 수 있다.
POST 요청 시에는 @RequestBody로 Users 객체를 맵핑할 것인데 우리는 userName만 JSON Body로 제공하면 된다.
이제 테스트를 진행해보자.
REST API 테스트
이제 서버를 실행시켜 서비스를 띄워주자.
HTTP 통신은 Postman, curl 등 편한 방법으로 요청하면 된다.
필자는 IntelliJ의 HTTP Client를 통해 요청을 보내보겠다.
POST http://localhost:8080/user
Content-Type: application/json
{
"userName" : "재훈맨"
}
###
POST http://localhost:8080/user
Content-Type: application/json
{
"userName" : "재훈걸"
}
###
POST http://localhost:8080/user
Content-Type: application/json
{
"userName" : "훈제맨"
}
###
POST http://localhost:8080/user
Content-Type: application/json
{
"userName" : "훈제걸"
}
###
GET http://localhost:8080/user
###
GET http://localhost:8080/user?userName=재훈
###
GET http://localhost:8080/user?userName=훈제
POST 요청 시
POST http://localhost:8080/user
Content-Type: application/json
Content-Length: 30
Connection: Keep-Alive
User-Agent: Apache-HttpClient/4.5.14 (Java/17.0.9)
Accept-Encoding: br,deflate,gzip,x-gzip
{
"userName" : "재훈맨"
}
의 내용을 가지고 create를 수행시킨 뒤, 정상적으로 처리가 됐다면
HTTP/1.1 200
Content-Type: text/plain;charset=UTF-8
Content-Length: 13
Date: Mon, 20 May 2024 09:15:05 GMT
Keep-Alive: timeout=60
Connection: keep-alive
등록 완료
의 메시지를 Response 받을 것이다.
총 4개를 등록하고 GET http://localhost:8080/user 요청을 보내면
HTTP/1.1 200
Content-Type: application/json
Transfer-Encoding: chunked
Date: Mon, 20 May 2024 09:17:44 GMT
Keep-Alive: timeout=60
Connection: keep-alive
[
{
"userId": 1,
"userName": "재훈맨"
},
{
"userId": 2,
"userName": "재훈걸"
},
{
"userId": 3,
"userName": "훈제맨"
},
{
"userId": 4,
"userName": "훈제걸"
}
]
의 요청을 받을 수 있을 것이다.
useName Parameter를 제공하지 않았으니 findAll()을 수행했다.
이제 userName의 Paramter를 제공해보자
[GET http://localhost:8080/user?userName=재훈]
[
{
"userId": 2,
"userName": "재훈걸"
},
{
"userId": 1,
"userName": "재훈맨"
}
]
[GET http://localhost:8080/user?userName=훈제]
[
{
"userId": 4,
"userName": "훈제걸"
},
{
"userId": 3,
"userName": "훈제맨"
}
]
예상대로 동작하는 모습을 확인할 수 있다.
간단하게 JPA를 사용하는 방법을 알아봤다.
다음에는 Query를 실행시키는 방식과 JPA 사용의 주의점을 알아보겠다.